
Применение XML в реляционных БД для хранения объектов сложной структуры
Источник: www.ibase.ru
База данных обычно имеет не самостоятельную ценность, является частью информационной системы. Независимо от того, сколько звеньев имеет эта система, на противоположном от БД конце находится интерфейс взаимодействия с пользователем, и задача программиста предоставить простой и понятный способ работы с хранящимися в БД данными и объектами. При всей своей отлаженности и очевидности, классический способ хранения и представления объектов развитой структуры имеет и вполне определенные недостатки, с которыми сталкивался любой разработчик, пытавшийся реализовать таким способом достаточно сложную систему.
Рассмотрим довольно стандартную ситуацию. В системе необходимо реализовать учет покупателей, со всеми их реквизитами, а таже, естественно, предоставить возможность их просмотра и редактирования. В классическом варианте нам необходимо:
1. Создать табличку
CUSTOMERS ( CUST_ID integer PK, NAME varchar (200), OKONH varchar(20), OKPO varchar(20), BIK varchar(20), COUNTRY varchar(50), CITY varchar(50), ... )
2. Создать форму редактирования с Label и DBEdit элементами, привязать их к соответствующим полям DataSet-а, и реализовать обычные обработчики кнопок "Добавить", "Удалить", "Изменить".

Пока все, вроде бы, просто. За исключением того, что однотипные формы в программе плодятся как кролики, отчего многие не выдерживают, и создают свой язык описания подобных форм, для динамического их создания. Сложности возникают, если:
- мы хотим вести учет не только юридических, а еще и физических лиц, для которых нужны дополнительные атрибуты, которые становятся бессмысленными для юрлиц (и наоборот).
- в процессе работы системы возникла необходимость добавить новый атрибут. Та же цепочка - поле в таблицу, изменения на форме, новая структура метаданных БД, новая программа.
- число некоторых атрибутов заранее неизвестно. Например, у организации может быть один телефон, 2, 3..10.
- система тиражируема, и в различных инсталляциях наборы атрибутов различаются кардинально.
В некоторых ситуациях, решить эти проблемы позволяет хранение вариантной части объекта в виде XML c соответствующей XSD схемой. В этом случае мы:
- Создаем табличку CUSTOMERS ( CUST_ID integer PK, NAME varchar (200), XML BLOB )
- В XSD-редакторе определяем необходимые нам типы.
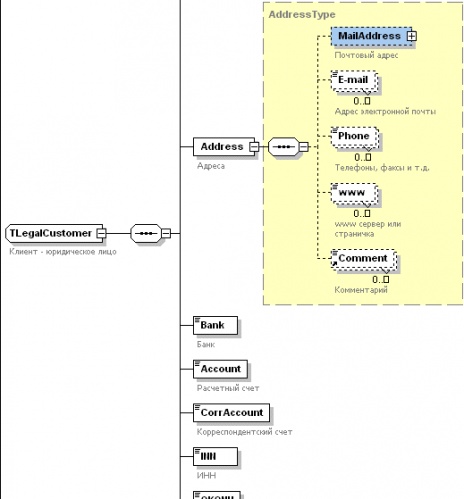
- В приложении вызываем универсальную форму редактирования, которой передаем соответствующий тип XSD схемы, и XML карточку.
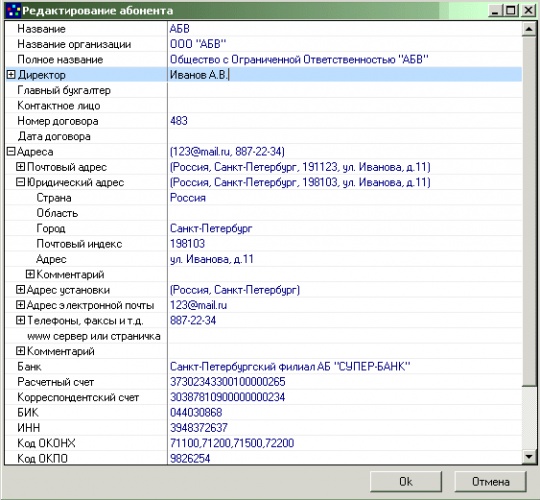
В примере, в качестве элемента редактирования используется адаптированный для работы с XML вариант Object Inspector.
За основу был взял TZPropList от Genadie Zuev, благо он бесплатный и с исходниками (http://www.torry.net/vcl/vcltools/objectinspectors/zproplst.zip). Таким же образом можно доработать любой Object Inpector - На входе он получает ссылку на два XML узла - XSD схема и собственно редактируемый объект. Если объект пустой, он создается на основе XSD схемы. Результат виден на картинках. Дополнительные бонусы - автозавершение и выпадающие списки для перечислимых типов, учет форматов и масок для прочих типов.
Каковы преимущества данной схемы:
- Даже на начальном этапе она менее трудоемка чем стандартная, и позволяет описывать объект в одном месте, причем как типы и размеры полей, так и их названия, заголовки и комментарии.
- Описание структуры объектов полностью хранится в БД, приложение о ней может ничего не знать.
- Средства описания форматов в XSD схемах заметно богаче набора типов данных
сервера.
Достаточно посмотреть на иерархию типов XSD. Кроме того, здесь возможно указание перечислений, диапазонов, максимальных и минимальных значений, а также масок использующих регулярные выражения. Пример типа использующего маску (почтовый индекс):<simpleType name='us-zipcode'> <restriction base='string'> <pattern value='[0-9]{5}(-[0-9]{4})?'/> </restriction> </simpleType> - Структура артибутов может быть древовидной, с произвольной степенью вложенности.
- Задав в схеме древовидную структуру и правила вхождения (0-1, 1, 1-n, 0-n), можно дать пользователю
возможность добавлять необходимое число однотипных атрибутов.
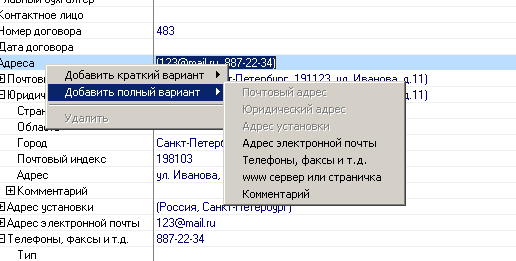
- Нет необходимости плодить формы редактирования.
- Возможно хранение объектов различной структуры в одной таблице.
- Добавление новых атрибутов требует только изменения схемы, и не влияет на работу системы. Данные будут продолжать храниться в старом формате, а новый атрибут будет добавлен в них при редактировании.
- Облегчается импорт/экспорт информации в другие системы.
Очевидным недостатком подобной схемы хранения, является невозможность использовать XML-атрибуты в условиях SQL запроса, а также выводить их в виде полей в Dataset. Однако, это в некоторой степени решается UDF функцией, выполняющей XPATH запрос к хранимому XML.
Например, запрос выбирающий всех клиентов из Москвы будет выглядеть так:
select * from customers where XPATH(XML, 'Address/MailAddress/City')='Москва'
Интересно, что в этом случае проявляется определенный полиморфизм - запрос выберет как физических так и юридических лиц, так как путь к атрибуту "Город" у них одинаков.
Или другой пример - выбрать 1-й и 2-й телефоны:
select xpath(XML, 'Address/Phone[0]'), xpath(XML, 'Address/Phone[1]') from customers
Стоит отметь, что вопреки ожиданиям работает такие запросы достаточно быстро, так как разбор XML - операция не затратная и выполняется за очень небольшое время. Практика показала применимость такого подхода на таблицах с десятками тысяч записей.
Для работы с большими объемами данных можно постоить индексы по наиболее часто используемым XML-атрибутам, в этом случае приведенный выше запрос выполняется практически мгновенно - для этого используется появившаяся в Yaffil возможность строить индексы по выражениям, в частности по UDF. Например, проиндексируем город в почтовом адресе:
create index CUST_CITY on CUSTOMERS computed by (xpath(XML, 'Address/MailAddress/City') COLLATE PXW_CYRL)
Теперь, запрос вида
select * from customers where xpath(XML, 'Address/MailAddress/City') COLLATE PXW_CYRL= 'Москва' COLLATE PXW_CYRL
выполняется с планом
PLAN (CUSTOMERS INDEX (CUST_CITY))
Другим недостатком является невозможность реализации ссылочной целостности. Здесь может быть два варианта - реализация ее на триггерах, либо введение для таких атрибутов SQL-полей дублеров c FK, заполняемых в триггерах.
Несмотря на эти и другие недостатки, схема имеет вполне конкретные применения, и во многих случаях значительно облегчает жизнь.
Ссылки по теме
Оставить комментарий
Комментарии


Но правельнее для УЧЁТА было бы использовать не реквизиты физ./юр. лиц, а реквизиты документов(прим. ПАСПОРТ)