
Техника Оптимизации Программ (фрагмент) 2/3
Программное непостоянство
В многозадачной среде, коей и является популярнейшая на сегодняшний день операционная система Windows, никакая программа не владеет всеми ресурсами системы единолично и вынуждена делить их с остальными задачами. А это значит, что скорость выполнения профилируемой программы не постоянна и находится в тесной зависимости от "окружающей среды". На практике разброс результатов измерений может достигать 10%-15%, а то и больше, особенно, если параллельно с профилировкой исполняются интенсивно нагружающие систему задачи.
Тем не менее, особой проблемы в этом нет, - достаточно лишь в каждом сеансе профилировки делать несколько контрольных прогонов и затем... нет, не усреднять, а выбирать замер с наименьшим временем выполнения. Дело в том, что измерения производительности - это не совсем обычные инструментальные измерения и типовые правила метрологии здесь неуместны. Процессор никогда не ошибается и каждый полученный результат точен. Другое дело, что он в той или иной степени искажен побочными эффектами, но! Никакие побочные эффекты никогда не приводят к тому, что программа начинает исполняться быстрее, нежели она исполняется в действительности, а потому, прогон с минимальным временем исполнения и представляет собой измерение в минимальной степени испорченное побочными эффектами.
Кстати, во многих руководствах утверждается, что перед профилировкой целесообразно выходить из сети ("что бы машина не принимала пакеты"), завершать все-все приложения, кроме самого профилировщика и вообще лучше даже "на всякий случай" перегрузиться. Все это чистейшей воды бред! Автор частенько отлаживал программы параллельно с работой в Word, приемом корреспонденции, загрузкой нескольких файлов из Интернета и при этом точность профилировки всегда оставалась удовлетворительной! Конечно, без особой нужды не стоит так рисковать, и параллельно работающие приложения перед началом профилировки, действительно, лучше завершить, но не следует доводить ситуацию до абсурда, и пытаться обеспечить полную "стерильность" своей машине.
Аппаратное непостоянство
Возможно, это покажется удивительным, но на аппаратном уровне время выполнения одних и тех же операций не всегда постоянно и подвержено определенным разбросам, под час очень большим и значительно превосходящим программную погрешность. Но, если последнюю, хотя бы теоретически, возможно ликвидировать (ну, например, запустить программу в однозадачном режиме), то аппаратное непостоянство неустранимо принципиально.
Почему оно - аппаратное непостоянство - вообще возникает? Ну, тут много разных причин. Вот, например, одна из них: если частота системной шины не совпадает с частотой модулей оперативной памяти, чипсету придется каждый раз выжидать случайный промежуток времени до прихода следующего фронта тактового импульса. Исходя из того, что один цикл пакетного обмена в зависимости от типа установленных микросхем памяти занимает от 5 до 9 тактов, а синхронизовать приходится и его начало, и его конец, нетрудно подсчитать, что в худшем случае мы получаем неоднозначность в 25%-40%.
Самое интересное, что аппаратный разброс в чрезвычайно высокой степени разниться от системы к системе. Я, к сожалению, так и не смог определить, кто именно здесь виноват, но могу сказать, что, к примеру, на P-III 733/133/100/I815EP не смотря на разницу в частотах памяти и системной шины, аппаратный разброс весьма невелик и едва ли превышает 1%-2%, на что можно вообще закрыть глаза.
Вот AMD Athlon 1050/100/100/VIA KT133 - совсем другое дело! У него наблюдается просто ошеломляющее аппаратное непостоянство, в частности, в операциях с основной памятью доходящее аж до двух раз! Непонятно, как на такой системе вообще можно профилировать программы? В, частности, последовательные замеры времени копирования 16-мегабайтного блока памяти после предварительной обработки (т. е. после отбрасывания заведомо пограничных значений) могут выглядеть так:
Прогон № 01: 84445103 тактов Прогон № 02: 83966665 тактов Прогон № 03: 73795939 тактов Прогон № 04: 80323626 тактов Прогон № 05: 84381967 тактов Прогон № 06: 85262076 тактов Прогон № 07: 85151531 тактов Прогон № 08: 91520360 тактов Прогон № 09: 92603591 тактов Прогон № 10: 100651353 тактов Прогон № 11: 93811801 тактов Прогон № 12: 84993464 тактов Прогон № 13: 92927920 тактов
Смотрите, расхождение между минимальным и максимальным временем выполнения составляет не много, не мало - 36%! А это значит, что вы не сможете обнаруживать "горячие" точки меньшей величины. Более того, вы не сможете оценивать степень влияния тех или иных оптимизирующих алгоритмов, если только они не дают, по меньшей мере, двукратного прироста производительности!
Отсюда правила:
- Не всякая система пригодна для профилировки и оптимизации приложений.
- Если последовательные замеры дают значительный временной разброс, просто смените систему.
Под "системой" в данном случае подразумевается не операционная система, а аппаратное обеспечение.
Обработка результатов измерений
Непосредственные результаты замеров времени исполнения программы в "сыром" виде, как было показано выше, ни на что ни годны. Очевидно, перед использованием их следует обработать. Как минимум откинуть пограничные значения, вызванные нерегулярными наведенными эффектами (ну, например, в самый ответственный для профилировки момент, операционная система принялась что-то сбрасывать на диск), а затем... Затем перед нами встает Буриданова проблема . Мы будем должны либо выбрать результат с минимальным временем исполнения - как наименее подвергнувшийся пагубному влиянию многозадачности, либо же вычислить наиболее типичное время выполнения - как время выполнения в реальных, а не идеализированных "лабораторных" условиях.
Мной опробован и успешно применяется компромиссный вариант, комбинирующий оба этих метода. Фактически, я предлагаю вам отталкиваться от среднеминимального времени исполнения. Сам алгоритм в общих чертах выглядит так: мы выполняем N повторов программы, а затем отбрасываем N/3 максимальных и N/3 минимальных результатов замеров. Для оставшихся N/3 замеров мы находим среднее арифметическое, которое и берем за основной результат. Величина N варьируется в зависимости от конкретной ситуации, но обычно с лихвой хватает 9-12 повторов, т. к. большее количество уже не увеличивает точности результатов.
Одна из возможных реализаций данного алгоритма приведена ниже:
Листинг 1.11. Нахождение среднетипичного времени выполнения
unsigned int cycle_mid(unsigned int *buff, int nbuff)
{
int a,xa=0;
if (!nbuff) nbuff=A_NITER;
buff=buff+1; nbuff--; // Исключаем первый элемент
if (getargv("$NoSort",0)==-1)
qsort(buff,nbuff,sizeof(int), \
(int (*)(const void *,const void*))(_compare));
for (a=nbuff/3;a<(2*nbuff/3);a++)
xa+=buff[a];
xa/=(nbuff/3);
return xa;
}
Проблема второго прохода
Для достижения приемлемой точности измерений профилируемое приложение следует выполнить, по крайней мере, 9-12 раз (см. предыдущий подразд. "Обработка результатов измерений"), причем каждый прогон должен осуществляться в идентичных условиях окружения. Увы! Без написания полноценного эмулятора всей системы это требование практически невыполнимо. Дисковый кэш, сверхоперативная память обоих уровней, буфера физических страниц и история переходов чрезвычайно затрудняют профилировку программ, поскольку при повторных прогонах время выполнения программы значительно сокращается.
Если мы профилируем многократно выполняемый цикл, то этим обстоятельством можно и пренебречь, поскольку время загрузка данных и/или кода в кэш практически не сказывается на общем времени выполнения цикла. К сожалению, так бывает далеко не всегда (такой случай как раз и был разобран в разд. "Информация о пенальти").
Да и можем же мы, наконец, захотеть оптимизировать именно инициализацию приложения?! Пускай, она выполняется всего лишь один раз за сеанс, но какому пользователю приятно, если запуск вашей программы растягивается на минуты а то и десятки минут? Конечно, можно просто перезагрузить систему, но... сколько же тогда профилировка займет времени?!
Хорошо. Очистить кэш данных - это вообще раз плюнуть. Достаточно считать очень большой блок памяти, намного превышающий его (кэша) емкость. Не лишнем будет и записать большой блок для выгрузки всех буферов записи (см. "Часть III. Подсистема кэш-памяти"). Это же, кстати, очистит и TLB (Translate Look aside Buffer) - буфер, хранящий атрибуты страниц памяти для быстрого обращения к ним (см. "предвыборка"). Аналогичным образом очищается и кэш/TLB от кода. Достаточно сгенерировать очень большую функцию, имеющую размер порядка 1-4 Мбайта, и при этом "ничего не делающую" (для определенности забьем ее машинными командами NOP - "нет операции"). Таким образом мы уменьшим пагубное влияние всех, перечисленных выше эффектов, хотя и не устраним его полностью. Увы! В этом мире есть вещи, не подвластные ни прямому, ни косвенному контролю (во всяком случае, на прикладном уровне).
С другой стороны, если мы оптимизируем одну, отдельно взятую функцию, (для определенности остановимся на функции реверса строк), то как раз таки ее первый прогон нам ничего и не даст, поскольку в данном случае основным фактором, определяющим производительность, окажется не эффективность кода/алгоритма самой функции, а накладные расходы на загрузку машинных инструкций в кэш, выделение и проецирование страниц операционной системой, загрузку обрабатываемых функцией данных в сверхоперативную память и т. д. В реальной же программе эти накладные расходы, как правило, уже устранены (даже если эта функция вызывается однократно).
Давайте проведем следующий эксперимент. Возьмем следующую функцию и десять раз подряд запустим ее на выполнение, замеряя время каждого прогона.
Листинг 1.12. Пример функции, однократно обращающийся к каждой загруженной в кэш ячейке
#define a (int *)((int)p + x)
A_BEGIN(0)
#define b (int *)((int)p + BLOCK_SIZE - x - sizeof(int))
for (x = 0; x < BLOCK_SIZE/2; x+=sizeof(int))
{
#ifdef __OVER_BRANCH__
if (x & 1)
#endif
*a = *a^*b; *b = *b^*a; *a = *a^*b;
}
A_END(0)
Для блоков памяти, полностью умещающихся в кэш-памяти первого уровня, на P-III 733/133/100/I815EP мы получим следующий ряд замеров:
__OVER_BRANCH__ not define __OVER_BRANCH__ is define 68586 63788 17629 18507 17573 18488 17573 18488 17573 18488 17573 18488 17573 18488 17573 18488
Обратите внимание, что время выполнения первого прогона функции (не путать с первой итерации цикла!) практически вчетверо превосходит все последующие! Причем, результаты замеров непредсказуемым образом колеблются от 62 190 до 91 873 тактов, что соответствует погрешности ~50%. Означает ли это, что, если данный цикл в реальной программе исполняется всего один раз, то оптимизировать его бессмысленно? Конечно же, нет! Давайте, для примера избавимся от этого чудачества с командой XOR и как нормальные люди обменяем два элемента массива через временную переменную. Оказывается, это сократит время первого прогона до 47 603-65 577 тактов, т. е. увеличит эффективность его выполнения на 20%-40%!
Тем не менее, устойчивая повторяемость результатов начинается лишь с третьего прогона! Почему так медленно выполняется первый прогон - это понятно (загрузка данных в кэш и прочее), но вот что не дает второму показать себя во всю мощь? Оказывается - ветвления. За первый прогон алгоритм динамического предсказания ветвлений еще не накопил достаточное количество информации и потому во втором прогоне еще давал ошибки, но, начиная с третьего, наконец-то "въехал" в ситуацию и понял, что от него ходят.
Убедиться, что виноваты именно ветвления, а не кто-нибудь другой, позволяет следующий эксперимент: давайте определим __OVER_BRANCH__ и посмотрим как это скажется на результат. Ага! Разница между вторым и третьим проходом сократилась с 0,3% до 0,1%. Естественно, будь наш алгоритм малость поветвистее (в том смысле, что содержит побольше ветвлений), и всех трех прогонов могло бы не хватить для накопления надежного статистического результата. С другой стороны, погрешность, вносимая переходами, крайне невелика и потому ей можно пренебречь. Кстати, обратите внимание, что постоянство времени выполнения функции на всех последних проходах соблюдается с точностью до одного такта!
Таким образом, при профилировании многократно выполняющихся функций, результаты первых двух-трех прогонов стоит вообще откинуть, и категорически не следует их арифметически усреднять.
Напротив, при профилировании функций, исполняющихся в реальной программе всего один раз, следует обращать внимание лишь на время первого прогона и отбрасывать все остальные, причем, при последующих запусках программы необходимо каким-либо образом очистить все кэши и все буфера, искажающие реальную производительность.
Проблема наведенных эффектов
Исправляя одни ошибки, мы всегда потенциально вносим другие и потому после любых, даже совсем незначительных модификаций кода программы, цикл профилировки следует повторять целиком.
Вот простой и очень типичный пример. Пусть в оптимизированной программе встретилась функция следующего вида:
Листинг 1.13. Фрагмент кода, демонстрирующий ситуацию, в которой удаление лишнего кода может обернуться существенным и труднообъясним падением производительности
ugly_func(int foo)
{
int a;
...
...
...
if (foo<1) return ERR_FOO_MUST_BE_POSITIVELY;
for(a=1; a <= foo; a++)
{
...
...
...
}
}
Очевидно, если попытаться передать функции ноль или отрицательное число, то цикл for_a не выполнится ни разу, а потому принудительная проверка значения аргумента (в тексте она выделена жирным шрифтом) бессмысленна! Конечно, при больших значениях foo накладные расходы на такую проверку относительно невелики, но в праве ли мы надеяться, что удаление этой строки, по крайней мере, не снизит скорость выполнения функции?
Постойте, это отнюдь не бредовый вопрос, относящийся к области теоретической абстракции! Очень может статься так, что удаление выделенной строки будет носить эффект прямо противоположный ожидаемому, и вместо того чтобы оптимизировать функцию, мы даже снизим скорость ее выполнения, причем, весьма значительно!
Как же такое может быть? Да очень просто! Если компилятор не выравнивает циклы в памяти (как, например, MS VC), то с довольно высокой степенью вероятности мы рискуем нарваться на кэш-конфликт (см. "Часть III. Подсистема кэш-памяти"), облагаемый штрафным пенальти. А можем и не нарваться! Это уж как фишка ляжет. Быть может, эта абсолютно бессмысленная (и, заметьте, однократно выполняемая) проверка аргументов как раз и спасала цикл от штрафных задержек, возникающих в каждой итерации.
Сказанное относится не только к удалению, но и вообще любой модификации кода, влекущий изменение его размеров. В ходе оптимизации производительность программы может меняться самым причудливым образом, то повышаясь, то понижаясь без всяких видимых на то причин. Самое неприятное, что подавляющее большинство компиляторов не позволяет управлять выравниванием кода и, если цикл лег по неудачным с точки зрения процессора адресам, все, что нам остается так это добавить в программу еще один кусок кода с таким расчетом, чтобы он вывел цикл из неблагоприятного состояния, либо же просто "перетасовать" код программы, подобрав самую удачную комбинацию.
"Идиотизм какой-то", - скажите вы и будете абсолютно правы. К счастью, тот же MS VC выравнивает адреса функций по адресам, кратным 0x20 (что соответствует размеру одной кэш-линейки на процессорах P6 и K6). Это исключает взаимное влияние функций друг на друга и ограничивает область тасования команд рамками всего "лишь" одной функции.
То же самое относится и к размеру обрабатываемых блоков данных, числу и типу переменных и т. д. Часто бывает так, что уменьшение количества потребляемой программой памяти приводит к конфликтам того или иного рода, в результате чего производительность естественно падает. Причем, при работе с глобальными и/или динамическими переменными мы уже не ограничивается рамками одной отдельно взятой функции, а косвенно воздействуем на всю программу целиком! (см. "Часть II. Конфликт DRAM банков").
Сформулируем три правила, которыми всегда следует руководствоваться при профилировке больших программ, особенно тех, что разрабатываются несколькими независимыми людьми. Представляете - в один "прекрасный" день вы обнаруживаете, что после последних внесенных вами "усовершенствований" производительность вверенного вам фрагмента неожиданно падает... Но, чтобы вы не делали, пусть даже выполнили "откат" к прежней версии, вернуть производительность на место вам никак не удавалось. А на завтра она вдруг - без всяких видимых причин! - сама восстанавливалась до прежнего уровня. Да, правильно, причина в том, что ваш коллега чуть-чуть изменил свой модуль, а это рикошетом ударило по вам!
Итак, обещанные правила:
- никогда-никогда не оптимизируйте программу "вслепую", полагаясь на "здравый смысл" и интуицию;
- каждое внесенное изменение проверяйте на "вшивость" профилировщиком и, если производительность неожиданно упадает, вместо того чтобы увеличиться, незамедлительно устраивайте серьезные "разборки": "кто виноват" и "чья тут собака порылась", анализируя весь, а не только свой собственный код;
- после завершения оптимизации локального фрагмента программы, выполните контрольную профилировку всей программы целиком на предмет обнаружения новых "горячих" точек, появившихся в самых неожиданных местах.
Проблемы оптимизации программ на отдельно взятой машине
Большинство программистов, особенно из тех, что "пасутся на вольных хлебах", имеют в своем распоряжении одну, ну максимум две машины, на которой и осуществляются все стадии создания программы: от проектирования до отладки и оптимизации. Между тем, как уже успел убедиться читатель "что русскому хорошо, то немцу - смерть".
Код, оптимальный для одной платформы, может оказаться совсем неоптимальным для другой. Планирование потоков данных (см. одноименную раздел части II) - яркое тому подтверждение. Ну, вспомните: особенности реализации предвыборки данных в чипсете VIA KT133 приводят к резкому падению производительности при параллельной обработке нескольких близко расположенных потоков. Об этом малоприятном факте умалчивает документация, он не может быть предварительно вычислен логически, - обнаружить его можно лишь экспериментально.
Совершенно недопустимо профилировать программу на одной-единственной машине, - это не позволит выявить все "узкие" места алгоритма. Следует, как минимум, охватить три-четыре типовые конфигурации, обращая внимания не только на модели процессоров, но и чипсетов. Этим вы более или менее застрахуете себя от "сюрпризов", подобных странностям чипсета VIA KT 133, описанным в данной книге.
Сложнее найти компромисс, наилучшим образом "вписывающийся" во все платформы. Вернее, не "сложнее", а вообще невозможно.
Краткий обзор современных профилировщиков
Существует не так уж и много профилировщиков, поэтому особой проблемы выбора у программистов и нет.
Если оптимизация - не ваш основной "хлеб", и эффективность для вас вообще не критична, то вам подойдет практически любой профилировщик, например тот, что уже включен в ваш компилятор. Более сложные профилировщики для вас окажутся лишь обузой, и вы все равно не разглядите заложенный в них потенциал, поскольку это требует глубоких знаний архитектуры процессора и всего компьютера в целом.
Если же вы всерьез озабоченны производительностью и качеством оптимизации ваших программ и планируете посвятить профилировке значительное время, то кроме Intel VTune и AMD Code Analyst вам ничто не поможет. Обратите внимание: не "Intel VTune или AMD Code Analyst", а именно "Intel VTune и AMD Code Analyst". Оба этих профилировщика поддерживают процессоры исключительно "своих" фирм и потому использование лишь одного из них - не позволит оптимизировать программу более чем наполовину.
Тем не менее, далеко не все читатели знакомы с этими продуктами и потому автор не может удержаться от соблазна, чтобы хотя бы кратко не описать их основные возможности.
Intel VTune
Бесспорно, что Vtune - это самый мощный из когда-либо существовавших профилировщиков, во всяком случае, на IBM PC (рис. 1.3). Собственно, его и профилировщиком язык то называть не поворачивается. VTune - это высокоинтеллектуальный инструмент, не только выявляющий "горячие" точки, но еще и дающий вполне конкретные советы по их устранению. В дополнении к этому, VTune содержит весьма не хилый оптимизатор кода, увеличивающий скорость программ, откомпилированных Microsoft Visual C++ 6.0 в среднем на 20%, - согласитесь, такая прибавка производительности никогда не бывает лишней!

В общем, у профилировщика VTune столько достоинств, что писать о них становится даже как-то и не интересно. Просто воспринимайте его как безальтернативный профилировщик и все! А в настоящем обзоре мы лучше поговорим о его недостатках (ну какая же программа обходится без недостатков?).
Основной недостаток VTune его чрезмерная "тяжелость" (дистрибьютив шестой версии - последней на момент написания этих строк - "весит" аж 150 Мбайт) и весьма впечатляющая стоимость, помноженная на тот факт, что, даже имея деньги, VTune не так-то просто приобрести в России. Правда, Intel предлагает бесплатную полнофункциональную версию, которая ни чем не уступает коммерческой, но работает всего лишь 30 дней. Скачивать такую "тяжесть" ради какого-то месяца работы? Извините, но это несерьезно! (Особенно, если у вас dial-up).
Другой минус - VTune не очень стабилен в работе и частенько "вешает" систему (например, у меня при попытке активизации некоторых счетчиков производительности он загоняет операционную систему в синий экран смерти с надписью "IRQL_NOT_LESS_OR_EQUAL" и хорошо если при этом еще не "грохает" активный Рабочий Стол!). Впрочем, если не лезть "куда не надо" и вообще перед выполнением каждого действия думать головой, то ужиться с VTune все-таки можно (а что делать - ведь достойной альтернативы все равно нет).
Еще VTune получает много нареканий за свою ужасающую сложность. Кажется, что вообще не возможно освоить его и досконально во всем разобраться. Один встроенный "хелп", занимающий свыше трех тысяч страниц формата A4 чего стоит! Попробуйте его прочесть (только прочесть) - даже если вы хорошо владеете английским, то это у вас отнимет, по меньшей мере, целый месяц! Но давайте рассмотрим проблему под другим углом. Вам нужен инструмент или бирюлька? Чем мощнее и гибче инструмент, - тем он сложнее по определению. С моей точки зрения VTune ничуть не сложнее чем тот же Visual C++ или Delphi и проблема заключается не в самой сложности, а в отсутствии литературы по профилировке вообще и данному продукту в частности. Поэтому, в данную книгу включен короткий самоучитель по VTune, который вы найдете в главе "Практический сеанс профилировки с VTune в десяти шагах", - надеюсь, это вам поможет.
AMD Code Analyst
Профилировщик AMD Code Analyst на два порядка уступает своему прямому конкуренту VTune, и я бы ни за что не порекомендовал использовать его в качестве вашего основного профилировщика (рис. 1.4).

Опасаясь быть побитым агрессивными поклонниками AMD, я все же позволю перечислить основные недостатки профилировщика Code Analyst:
- Во-первых, Code Analyst требует обязательно наличия отладочной информации в профилируемой программе. Программу без отладочной информации он просто откажется загружать! Компиляторы же, в подавляющем своем большинстве, никогда не помещают отладочную информацию в оптимизированные программы. Это объясняется тем, что оптимизация, внося значительные изменения в исходный код, уничтожает прямое соответствие между номерами строк программы и сгенерированными машинными инструкциями. Фактически, оптимизированная и не оптимизированная программа - это две разные программы, имеющие различные, пусть и пересекающиеся, подмножества "горячих" точек. Профилировка не оптимизированного варианта программы принципиально не позволяет найти и устранить все узкие места настоящего приложения. (При отключенной оптимизации узкие места могут быть найдены там, где их и нет).
- Во-вторых, разрешающая способность диаграмм профилировщика Code Analyst ограничивается строками исходного текста программы, но, увы, не машинными командами (как у VTune). И хотя в принципе Code Analyst позволяет определять время выполнения каждой инструкции, он не предоставляет никаких механизмов выделения "горячих" точек на этом уровне. Всю работу по выявлению "тяжеловесных" машинных команд приходится выполнять самостоятельно, "вручную" просматривая столбик цифр колонки CPI (Cycle per Instruction - Циклов на Инструкцию). Надо ли говорить, что даже в относительно небольшом участке программы количество машинных команд может достигать нескольких тысяч и подобный "кустарный" анализ их "температур" может растянуться черт знает на сколько времени.
- В-третьих, Code Analyst не дает никаких советов по ликвидации выявленных узких мест программы, что не очень-то обрадует программистов-новичков (а таковых, как показывает практика, большинство и лишь очень немногие из нас поднаторели в оптимизации).
- В-четвертых, профилировщик Code Analyst просто неудобен в работе. Неразвитая система контекстных меню, крайне не конфигурабельный и вообще аскетичный интерфейс, отсутствие возможности сохранения "хронологии" профилировки... все это придает ему черты незаконченной утилиты, написанной на скорую руку.
Тем не менее, Code Analyst весьма компактен (его последняя на данный момент версия 1.1.0 занимает всего 16 Мбайт, что на порядок меньше VTune), стабилен и устойчив в работе и главное - он содержит полноценный эмулятор процессоров K6-II, Athlon (с внешним и интегрированным кэшем), Duron, включая и их мобильные реализации. Причем, есть возможность вручную выбирать частоту шины и ядра. Это полезно хотя бы для оценки влияния частоты шины на производительность, что особенно актуально для приложений интенсивно работающих с основной оперативной памятью (жалко, но VTune лишен этой "вкусности"). Наконец, Code Analyst содержит толковую справку, сжато и внятно описывающую узкие места процессора. И - самое приятное - он, в отличие от VTune, абсолютно бесплатен (во всяком случае, пока...)!
В конечном счете, независимо от степени своих симпатий (антипатий) к этому профилировщику, правило хорошего тона программирования обязывают использовать его для оптимизации ваших приложений под процессор Athlon, который занимает весьма существенную долю рынка и этим фактом нельзя пренебрегать!
Microsoft profile.exe
Профилировщик Microsoft profile.exe настолько прост и незатейлив, что даже не имеет собственного имени и нам, на протяжении всей книги, придется называть его по имени исполняемого файла (рис. 1.5).
Profile.exe - чрезвычайно простой и минимально функциональный профилировщик, попадающий в этот обзор лишь потому, что он входит в штатную поставку компилятора Microsoft Visual C++ (редакции - Professional и Enterprise), а потому достается большинству из нас практически даром, в то время как остальные профилировщики приходится где-то искать, скачивать или покупать.
Пишем собственный профилировщик
Какой смыл разрабатывать свой собственный профилировщик, если практически с каждым компилятором уже поставляется готовый? А если возможностей штатного профилировщика окажется недостаточно, то - пожалуйста - к вашим услугам AMD Code Analyst и Intel VTune.
К сожалению, штатный профилировщик Microsoft Visual Studio (как и многие другие подобные ему профилировщики) использует для измерений времени системный таймер, "чувствительности" которого явно не хватает для большинства наших целей. Профилировщик Intel VTune слишком "тяжел" и, кроме того, не бесплатен, а AMD Code Analyst не слишком удобен в работе и нет ни каких гарантий, что завтра за него придется платить. Все это препятствует использованию перечисленных выше профилировщиков в качестве основных инструментов данной книги.
Предлагаемый автором DoCPU Clock, собственно, и профилировщиком язык назвать не поворачивается. Он не ищет "горячие" точки, не подсчитывает количество вызовов, более того, вообще не умеет работать с исполняемыми файлами. DoCPU Clock представляет собой более чем скромный набор макросов, предназначенных для непосредственно включения в исходный текст программы, и определяющих время выполнения профилируемых фрагментов. В рамках данной книги этих ограниченных возможностей оказывается вполне достаточно. Ведь все, что нам будет надо, так это оценить влияние тех или иных оптимизирующих алгоритмов на производительность.
Краткое описание профилировщика DoCPU Clock
Подробное описание профилировщика DoCPU Clock содержится в его исходном файле и по соображениям экономии места здесь не приводится.
Практический сеанс профилировки с VTune в десяти шагах
Любой, даже самый совершенный, инструмент бесполезен, если мастер не умеет держать его в руках. Профилировщик VTune не относится к категории интуитивно-понятных программных продуктов, которые легко осваиваются методом "тыка". VTune - это профессиональный инструмент, и грамотная работа с ним немыслима без специального обучения. В противном случае, большой пласт его функциональных возможностей так и останется незамеченным, заставляя разработчика удивленно пожимать плечами "и что только в этом VTune остальные нашли?".
Настоящая глава, на учебник не претендует, но автор все же надеется, что она поможет сделать вам в освоении VTune первые шаги и познакомиться с его основными функциональными возможностями и к тому же поможет вам решать: стоит ли использовать VTune или же лучше остановить свой выбор на более простом и легком в освоении профилировщике.
В качестве "подопытного кролика" для наших экспериментов с профилировкой и оптимизацией мы используем простой переборщик паролей. Почему именно переборщик? Во-первых, это наглядный и вполне реалистичный пример, а, во-вторых, в программах подобного рода требование к производительности превыше всего. Предвидя возможное негодование некоторых читателей, сразу же замечу, что ни о каком взломе настоящих шифров и паролей здесь речь не идет! Реализованный в программе криптоалгоритм не только нигде не используется в реальной жизни, но к тому же допускает эффективную атаку, раскалывающую зашифрованный текст практически мгновенно.
В первую очередь нас будет интересовать не сам взлом, а техника поиска "горячих" точек и возможные способы их ликвидации. Словом, ничуть не боясь оскорбить свою пуританскую мораль, набейте в редакторе исходный тест следующего содержания:
Листинг 1.14. [Profile/pdsw.cНе оптимизированный вариант парольного переборщика
//----------------------------------------------------------------------
// Это пример того, как не нужно писать программы! Здесь допущено множество
// ошибок, снижающих производительность. Профилировка позволяет найти их все
// ---------------------------------------------------------------------
// КОНФИГУРАЦИЯ
#define ITER 100000 // макс. итераций
#define MAX_CRYPT_LEN 200 // макс. длина шифротекста
// процедура расшифровки шифротекста найденным паролем
DeCrypt(char *pswd, char *crypteddata)
{
int a;
// указатель текущей позиции расшифровываемых данных
int p = 0;
// * * * ОСНОВНОЙ ЦИКЛ РАСШИФРОВКИ * * *
do {
// расшифровываем текущий символ
crypteddata[p] ^= pswd[p % strlen(pswd)];
// переходим к расшифровке следующего символа
} while(++p < strlen(crypteddata));
}
// процедура вычисления контрольной суммы пароля
int CalculateCRC(char *pswd)
{
int a;
int x = -1; // ошибка вычисления CRC
// алгоритм вычисления CRC, конечно, кривой как бумеранг, но
// ногами чур его не пинать, - это делалось исключительно
// для того, чтобы продемонстрировать missaling
for (a = 0; a < strlen(pswd); a++) x += *(int *)((int)pswd + a);
return x;
}
// процедура проверки контрольной суммы пароля
int CheckCRC(char *pswd, int validCRC)
{
if (CalculateCRC(pswd) == validCRC)
return validCRC;
// else
return 0;
}
// процедура обработки текущего пароля
do_pswd(char *crypteddata, char *pswd, int validCRC, int progress)
{
char *buff;
// вывод текущего состояния на терминал
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
// проверка CRC пароля
if (CheckCRC(pswd, validCRC))
{ // <- CRC совпало
// копируем шифроданные во временный буфер
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata);
// расшифровываем
DeCrypt(pswd, buff);
// выводим результат расшифровки на экран
printf("CRC %8X: try to decrypt: \"%s\"\n",
CheckCRC(pswd, validCRC),buff);
}
}
// процедура перебора паролей
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC)
{
int a;
int p = 0;
// генерировать пароли
for(a = 0; a < max_iter; a++)
{
// обработать текущий пароль
do_pswd(crypteddata, pswd, validCRC, 100*a/max_iter);
// * основной цикл генерации паролей *
// по алгоритму "защелка" или "счетчик"
while((++pswd[p])>'z')
{
pswd[p] = '!';
p++; if (!pswd[p])
{
pswd[p]=' ';
pswd[p+1]=0;
}
} // end while(pswd)
// возвращаем указатель на место
p = 0;
} // end for(a)
return 0;
}
// Функция выводит число, разделяя разряды точками
print_dot(float per)
{
// * * * КОНФИГУРАЦИЯ * * *
#define N 3 // отделять по три разряда
#define DOT_SIZE 1 // размер точки-разделителя
#define DOT "." // разделитель
int a;
char buff[666];
sprintf(buff,"%0.0f", per);
for(a = strlen(buff) - N; a > 0; a -= N)
{
memmove(buff + a + DOT_SIZE, buff + a, 66);
if(buff[a]==' ') break;
else
memcpy(buff + a, DOT, DOT_SIZE);
}
// выводиим на экран
printf("%s\n",buff);
}
main(int argc, char **argv)
{
// переменные
FILE *f; // для чтения исходного файла (если есть)
char *buff; // для чтения данных исходного файла
char *pswd; // текущий тестируемый пароль (need by gen_pswd)
int validCRC; // для хранения оригинального CRC пароля
unsigned int t; // для замера времени исполнения перебора
int iter = ITER; // макс. кол-во перебираемых паролей
char *crypteddata; // для хранения шифрованных
// build-in default crypt
// кто прочтет, что здесь зашифровано, тот постигнет Великую Тайну
// Крис Касперски ;)
char _DATA_[] = "\x4B\x72\x69\x73\x20\x4B\x61\x73\x70\x65\x72\x73\x6B"\
"\x79\x20\x44\x65\x6D\x6F\x20\x43\x72\x79\x70\x74\x3A"\
"\xB9\x50\xE7\x73\x20\x39\x3D\x30\x4B\x42\x53\x3E\x22"\
"\x27\x32\x53\x56\x49\x3F\x3C\x3D\x2C\x73\x73\x0D\x0A";
// TITLE
printf( "= = = VTune profiling demo = = =\n"\
"==================================\n");
// HELP
if (argc==2)
{
printf("USAGE:\n\tpswd.exe [StartPassword MAX_ITER]\n");
return 0;
}
// выделение памяти
printf("memory malloc\t\t");
buff = (char *) malloc(MAX_CRYPT_LEN);
if (buff) printf("+OK\n"); else {printf("-ERR\n"); return -1;}
// получение шифротекста для расшифровки
printf("get source from\t\t");
if (f=fopen("crypted.dat","r"))
{
printf("crypted.dat\n");
fgets(buff,MAX_CRYPT_LEN, f);
}
else
{
printf("build-in data\n");
buff=_DATA_;
}
// выделение CRC
validCRC=*(int *)((int) strstr(buff,":")+1);
printf("calculate CRC\t\t%X\n",validCRC);
if (!validCRC)
{
printf("-ERR: CRC is invalid\n");
return -1;
}
// выделение шифрованных данных
crypteddata=strstr(buff,":") + 5;
//printf("cryptodata\t\t%s\n",crypteddata);
// выделение памяти для парольного буфера
printf("memory malloc\t\t");
pswd = (char *) malloc(512*1024); pswd+=62;
/* демонстрация последствий ^^^^^^^^^^^ не выровненных данных */
/* размер блока объясняется тем, что при запросе таких блоков */
/* malloc всегда выравнивает адрес на 64 Кб, что нам и надо */
memset(pswd,0,666); // <-- инициализация
if (pswd) printf("+OK\n"); else {printf("-ERR\n"); return -1;}
// разбор аргументов командной строки
// получение стартового пароля и макс. кол-ва итераций
printf("get arg from\t\t");
if (argc>2)
{
printf("command line\n");
if(atol(argv[2])>0) iter=atol(argv[2]);
strcpy(pswd,argv[1]);
}
else
{
printf("build-in default\n");
strcpy(pswd,"!");
}
printf("start password\t\t%s\nmax iter\t\t%d\n",pswd,iter);
// начало перебора паролей
printf("==================================\ntry search... wait!\n");
t=clock();
gen_pswd(crypteddata,pswd,iter,validCRC);
t=clock()-t;
// вывод кол-ва перебираемых паролей за сек
printf(" \rPassword per sec:\t");
print_dot(iter/(float)t*CLOCKS_PER_SEC);
return 0;
}
Откомпилировав этот пример с максимальной оптимизацией, запустим его на выполнение, чтобы убедиться насколько хорошо справился со своей работой машинный оптимизатор.
Прогон программы на P-III 733 даст скорость перебора всего лишь порядка 30 тысяч паролей в секунду! Да это меньше, чем совсем ничего и такими темпами зашифрованный текст будет "ломаться" ну очень долго! Куда же уходят такты процессора?
Для поиска узких мест программы мы воспользуемся профилировщиком Intel VTune. Запустим его (не забывая, что под Windows 2000/NT он требует для своей работы привилегий администратора) и, тем временем пока компьютер деловито шуршит винчестером, создадим таблицу символов (не путать с отладочной информацией!), без которой профилировщик ни за что не сможет определить какая часть исполняемого кода к какой функции относится. Для создания таблицы символов в командной строке компоновщика (линкера) достаточно указать ключ /profile. Например, это может выглядеть так: link /profile pswd.obj. Если все сделано правильно, образуется файл pswd.map приблизительно следующего содержания:
0001:00000000 _DeCrypt 00401000 f pswd.obj 0001:00000050 _CalculateCRC 00401050 f pswd.obj 0001:00000080 _CheckCRC 00401080 f pswd.obj
Ага, VTune уже готов к работе и терпеливо ждет наших дальнейших указаний, предлагая либо открыть существующий проект - "Open Existing Project" (но у нас нечего пока открывать), либо вызывать Мастера для создания нового проекта - "New Project Wizard" (вот это, в принципе, нам подходит, но сумеем ли мы разобраться в настойках Мастера?), либо же выполнить быстрый анализ производительности приложения - "Quick Performance Analyses", - выбираем последнее! В появившемся диалогом окне указываем путь к файлу pswd.exe и нажимаем кнопку "GO" (то есть "Иди").
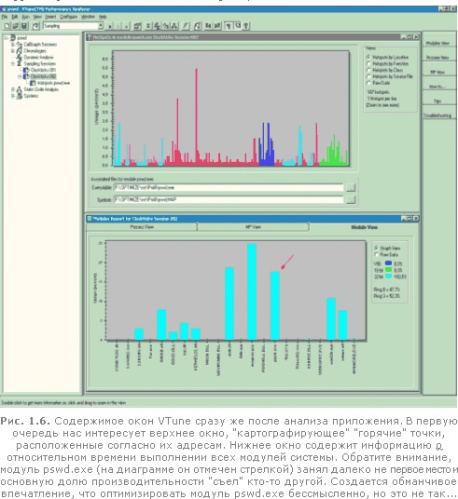
VTune автоматически запускает профилируемое приложение и начинает собирать информацию о времени его выполнения в каждой точке программы, сопровождая этот процесс симпатичной змейкой - индикатором. Если нам повезет, и мы не "зависнем", то через секунду-другую VTune распахнет себя на весь экран и выведет несколько окон с полезной и не очень информацией. Рассмотрим их поближе (см. рис. 1.6). В левой части экрана находится Навигатор Проекта, позволяющий быстро перемещаться между различными его части. Нам он пока не нужен и потому сосредоточим все свое внимание в центр экрана, где расположены окна диаграмм.
Верхнее окно показывает сколько времени выполнялась каждая точка кода, позволяя тем самым обнаружить "горячие" точки (Hot Spots), т. е. те участки программы, на выполнение которых уходит наибольшее количество времени. В данном случае профилировщик обнаружил 187 "горячих" точек, о чем и уведомил нас в правой части окна. Обратите внимание на два пика, расположение чуть левее середины центра экрана. Это не просто "горячие", а прямо-таки "адски раскаленные" точечки, съедающие львиную долю быстродействия программы, и именно с их оптимизации и надо начинать!
Подведем курсор к самому высокому пику - VTune тут же сообщит, что оно принадлежит функции out. Постой! Какой out?! Мы ничего такого не вызывали! Кто же вызвал эту "нехорошую" функцию? (Несомненно, вы уже догадались, что это сделала функция printf, но давайте притворимся будто бы мы ничего не знаем, ведь в других случаях найти виновника не так просто).
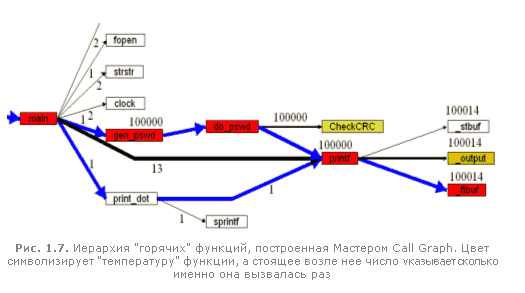
Чтобы не рыскать бес толку по всему коду, воспользуемся другим инструментом профилировщика - "Call Graph", позволяющим в удобной для человека форме отобразить на экране иерархическую взаимосвязь различных функций (или классов, если вы пишите на Си ++).
В меню Run выбираем пункт Win32* Call Graph Profiling Session и вновь идем перекурить, пока VTune профилирует приложение. По завершению профилировки на экране появится еще два окна. Верхнее, содержащее электронную таблицу, мы рассматривать не будем (оно понятно и без слов), а вот к нижнему присмотримся повнимательнее. Пастельно-желтый фон украшают всего два ядовито-красных прямоугольника с надписями "Thread 400" и "mainCRTStartup". Щелкнем по последнему из них два раза, - профилировщик VTune тут же выбросит целый веер дочерних функций, вызываемых стартовым кодом приложения. Находим среди них main (что будет очень просто, т. к. только main выделен красным цветом) и щелкаем по нему еще раз.... и будем действовать так до тех пор, пока не раскроем все дочерние функции процедуры main.
В результате выяснится, что функцию out действительно вызывает функция printf, а саму printf вызывает... do_pswd. Ну, да! Теперь мы "вспомнили", что использовали ее для вывода текущего тестируемого пароля на экран! Какая глупая идея! Вот оказывается куда ушла вся производительность!
Шаг первый. Удаление printf
Конечно, полностью отказываться от вывода текущего состояния программы - глупо (пользователю ведь интересно знать сколько паролей уже перебрано, и потом надо ведь как-то контролировать машину - не "зависла" ли?), но можно ведь отображать не каждый перебираемый пароль, а скажем, каждый шестисотый, а еще лучше - каждый шеститысячный. При этом накладные расходы на вызов функции printf значительно упадут, а то и вовсе приблизятся к нулю.
Давайте перепишем фрагмент, ответственный за вывод текущего состояния следующим образом (листинг 1.15).
Листинг 1.15. Сокращение количества вызова функции printf
static int x=0;
// вывод текущего состояния на терминал
if (++x>6666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Батюшки мои! После перекомпиляции мы получаем скорость перебора свыше полутора миллионов паролей в секунду! То есть скорость программы возросла более чем в пять раз! Программа выполняется так быстро, что "чувствительности" функции clock уже оказывается недостаточно для измерений и количество итераций приходится увеличивать раз в сто! И это, как мы убедимся в самом непосредственном будущем, еще отнюдь не предел быстродействия!
Шаг второй. Вынос strlen за тело цикла
Повторный запуск "обновленной" программы под профилировщиком показывает, что количество "горячих" точек в ней уменьшилось с 187 до 106. Конечно, это хорошо, но ведь "горячие" точки все еще есть! Кликнув в области Views, расположенной в правом верхнем углу диалогового окна HotSpots in module по переключателю Hotspots by Function (сортировать "горячие" точки по функциями), мы узнаем, что ~80% времени наша программа проводит в недрах функции Calculate CRC, затем с большим отрывом следует gen_pswd - ~12% и по ~3% делят функции Check CRС и do_pswd.
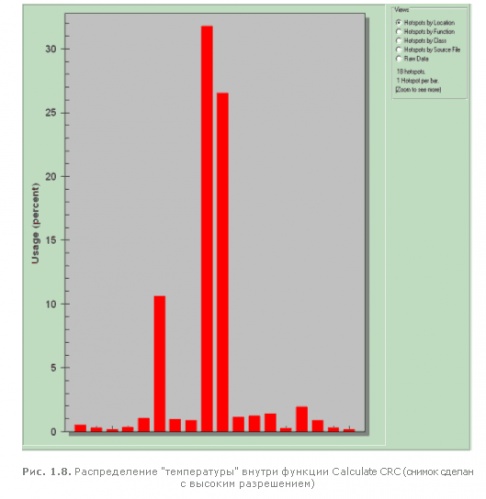
Ну это никуда не годится! Какая-то там жалкая функция Calculate CRC без зазрения совести поглощает практически все быстродействие программы! Эх, вот бы еще узнать, какая именно часть функции в наибольшей степени влияет на производительность. И профилировщик VTune позволяет это сделать!
Дважды кликнем по красному прямоугольнику, чтобы увеличить его на весь экран. Оказывается, внутри функции Calculate CRC насчитывается 18 "горячих" точек, три их которых наиболее "горячи" - ~30%, ~25% и ~10% соответственно (рис. 1.8). Вот с первой из них мы и начнем. Дважды кликнем по самому высокому из прямоугольников и, профилировщик VTune обижено пискнув, сообщит, что "No source found for offset 0x69 into F:\.OPTIMIZE\src\Profil\pswd.exe. Proceed with disassembly only?" ("Исходные тексты не найдены. Продолжать с отображением только дизассемблерного текста?"). Действительно, поскольку программа откомпилирована без отладочной информации, то профилировщик VTune не может знать, какой байт ассемблерного когда, какой строке соответствует, а компилятор не соглашается предоставить эту информацию в силу того, что в оптимизированной программе соответствие между исходным текстом и сгенерированным машинным кодом, в общем-то, не столь однозначно.
Конечно, можно профилировать и не оптимизированную программу, но какой в этом резон? Ведь это будет другая программа и с другими "горячими" точками! В любом случае, качественная оптимизация без знаний ассемблера невозможна, поэтому, прогнав все страхи прочь, смело нажмем на кнопку ОК, то есть "Да, мы соглашаемся работать без исходных текстов непосредственно с ассемблерным кодом".
Профилировщик VTune тут же "тыкает нас носом" в инструкцию REPNE SCANB. Не нужно быть провидцем, чтобы распознать в ней ядро функции strlen. Использовали ли мы функцию strlen в исходном тексте программы? А то как же! Смотрим следующий листинг 1.16.
Листинг 1.16. Вызов функции strlen в заголовке цикла привел к тому, что компилятор, не распознав в ней инварианта, не вынес ее из цикла, "благодаря" чему длина одной и той же строки стала подсчитываться на каждой итерации
int CalculateCRC(char *pswd)
{
int a;
int x = -1; // ошибка вычисления CRC
for (a = 0; a < strlen(pswd); a++)
x += *(int *)((int)pswd + a);
return x;
}
Судя по всему, бестолковый компилятор не вынес вызов функции strlen за тело цикла, хотя ее аргумент - переменная pswd не модифицировалась в цикле! Хорошо, если гора не идет к Магомету, пойдем навстречу компилятору и перепишем этот участок кода так:
Листинг 1.17. Вынос функции strlen за пределы цикла
int length; length=strlen(pswd); for (a = 0; a < length; a++)
Перекомпилировав программу, мы с удовлетворением отметим, что теперь ее быстродействие возросло до трех с половиной миллионов паролей в секунду, т. е. практически в два с половиной раза больше, чем было в предыдущем случае.
Шаг третий. Выравнивание данных
Тем не менее, профилировка показывает, что количество "горячих" точек не только сократилось, но даже и возросло на одну! Почему? Так дело в том, что алгоритм подсчета "горячих" точек учитывает не абсолютное, а относительное быстродействие различных частей программы по отношению друг к другу. И по мере удаления самых больших пиков, на диаграмме появится более мелкая "рябь".
Несмотря на оптимизацию, функция Calculate CRC, по прежнему идет "впереди планеты всей", отхватывая более 50% всего времени исполнения программы. Но теперь самой "горячей" точной становится пара команд:
mov edi, DWORD PTR [eax+esi] add edx, edi
Хм! Что же в них такого особенного? Ну да, тут налицо обращение к памяти (x += *(int *)((int)pswd + a)), но ведь тестируемый пароль по идее должен находится в кэше первого уровня, доступ к которому занимает один такт. Может быть, кто-то вытеснил эти данные из кэша? Или произошел какой-нибудь конфликт? Попробуй тут разберись! Можно бесконечно ломать голову, поскольку причина вовсе не в этом коде, а совсем в другой ветке программы.
Вот тут самое время прибегнуть к одному из мощнейших средств профилировщика Vtune, т. е. к динамическому анализу, позволяющему не только определить куда "уходят" такты, но и выяснить причины этого. Причем, динамический анализ выполняется отнюдь не на "живом" процессоре, а на его программном эмуляторе. Это здорово экономит ваши финансы! Для оптимизации вовсе не обязательно приобретать всю линейку процессоров - от Intel 486 до Pentium-4, - вполне достаточно приобрести один профилировщик VTune, и можете запросто оптимизировать свои программы под Pentium-4, имея в наличии всего лишь Pentium-II или Pentium-III.
Перед началом динамического анализа, вам требуется указать какую именно часть программы вы хотите профилировать. В частности, можно анализировать как одну "горячую" точку функции Calculate CRC, так и всю функцию целиком. Поскольку, наша подопечная функция содержит множество "горячих" точек, выберем последний вариант.
Прокручивая экран вверх, переместим курсор в строку с меткой Calculate CRC (метки отображаются в второй слева колонке экрана). Если же такой строки не окажется, найдем на панели инструментов кнопку, с голубым треугольником, направленным вверх (Scroll to Previous Portal) и нажмем ее. Теперь установим точку входа (Dynamic Analyses Entry Pont), которая задается кнопкой с желтой стрелкой, направленной вправо. Аналогичным образом задается и точка выхода (Dynamic Analyses Exit Pont) - прокручивая экран вниз, добираемся до последней строки Calculate CRC (она состоит всего из одной команды - ret) и, пометив ее курсором, нажимаем кнопку с желтой стрелкой, направленной налево. Теперь - "Run\Dynamic Analysis Session". В появившимся диалоговом окне выбираем эмулируемую модель процессора (в нашем случае - P-III) и нажимаем кнопку Start. Поехали!
Профилировщик вновь запустит программу и, погоняя ее минуту-другую, выдаст приблизительно следующее окно (рис. 1.9).
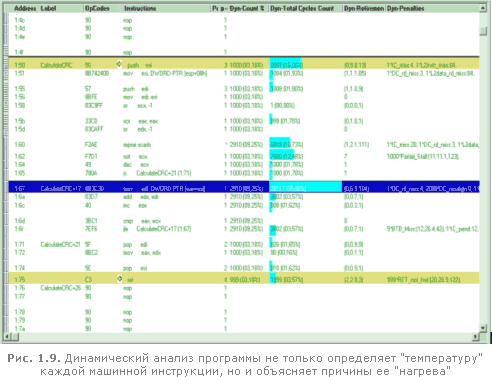
Ага! Вот она наша "горячая" точка (на рисунке она отмечена курсором). Двойной щелчок мыши вызывает информационный диалог, подробно описывающий проблему (листинг 1.18).
Листинг 1.18.
Decoder Minimum Clocks = 0, ; // Минимальное время декодирования 0 тактов Decoder Average Clocks = 0.7 ; // Среднее время декодирования 0.7 тактов Decoder Maximum Clocks = 14 ; // Максимальное время декодирования 14 тактов Retirement Minimum Clocks = 0, ; // Минимальное время завершения 0 тактов Retirement Average Clocks = 6.9 ; // Среднее время завершения 6.9 тактов Retirement Maximum Clocks = 104 ; // Максимальное время завершения 104 такта Total Cycles = 20117 (35,88%) ; // Полное время исполнения 20.117 тактов // Инструкция декодируется в одну микрооперацию Micro-Ops for this instruction = 1 // Инструкция ждала (0, 0.1, 2) цикла пока ее операнды не были готовы The instruction had to wait (0,0.1,2) cycles for it's sources to be ready Warnings: 3*decode_slow:0 ; // Конфликтов декодеров - нет Dynamic Penalty: DC_rd_miss The operand of this load instruction was not in the data cache. The instruction stalls while the processor loads the specified address location from the L2 cache or main memory. (Операнд этой инструкции отсутствовал в кэше данных. Инструкция ожидала пока процессор загрузит соответствующие данные из кэша второго уровня или основной памяти). Occurrences = 1 ; // Случалось один раз Dynamic Penalty: DC_misalign The instruction stalls because it accessed data that was split across two data-cache lines. (Инструкция простаивала, потому что она обращалась к данным "расщепленным" через две кэш-линии) Occurrences = 2000 ; // Случалось 2000 раз Dynamic Penalty: L2data_rd_miss The operand of this load instruction was not in the L2 cache. The instruction stalls while the processor loads the specified address location from main memory. (Операнд этой инструкции отсутствовал в кэше второго уровня. Инструкция ожидала пока процессор загрузит соответствующие данные из основной памяти). Occurrences = 1 ; // Случалось один раз Dynamic Penalty: No_BTB_info The BTB does not contain information about this branch. The branch was predicted using the static branch prediction algorithm. (BTB - Branch Target Buffer - буфер ветвлений не содержал информацию об этом ветвлении. Ветка была предсказана статическим алгоритмов предсказаний). Occurrences = 1 ; // Случалось один раз
Какая богатая кладезь информации! Оказывается, кэш тут действительно не причем (кэш-промах произошел всего один раз), а основной виновник - доступ к не выровненным данным, который имел место аж 2000 раз, - именно столько, сколько и прогонялась программа. Таким образом, такое происшествие случалось на каждой итерации цикла - отсюда и "тормоза".
Смотрим, - где в программе инициализируется указатель pswd? Ага, вот фрагмент кода из тела функции main (надеюсь, теперь вам понятно, почему статический анализ функции Calculate CRC был неспособен что-либо дать?):
Листинг 1.19. Выравнивание парольного буфера для предотвращения штрафных санкций со стороны процессора
pswd = (char *) malloc(512*1024); pswd+=62;
Убираем строку pswd += 62 и перекомпилируем программу. Теперь быстродействие соствило четыре с половиной миллиона паролей в секунду! Держи тигра за хвост!
Шаг четвертый. Избавление от функции strlen
Возвращаясь к рис. 1.9 отметим, что обращение к не выровненным данным - не единственная "горячая" точка функции Calculate CRC. С небольшим отрывом за ней следует инструкция PUSH, временно сохраняющая регистры в стеке и... опять та противная функция strlen с которой мы уже сталкивались.
Действительно, вычисление длины пароля вполне сопоставимо по времени с подсчетом его контрольной суммы. Вот если бы этого удалось избежать. А для чего собственно, вообще вычислять длину каждого пароля? Ведь пароли перебираются не хаотично, а генерируются по вполне упорядоченной схеме и приращение длины пароля на единицу происходит не так уж и часто. Так, может быть, лучше возложить эту задачу на функцию gen_pswd? Пусть при первом же вызове она определяет длину начального пароля, а затем при "растяжке" строки увеличивает глобальную переменную length на единицу. Сказано - сделано.
Теперь код функции gen_pswd выглядит так:
Листинг 1.20. Удаление функции strlen и "ручное" приращение длины пароля при его удлинении на один символ
int a;
int p = 0;
length = strlen(pswd); // определение длины начального пароля
...
if (!pswd[p])
{
pswd[p]=' ';
pswd[p+1]=0;
length++; // "ручное" увеличение длины пароля
}
...
А код функции Calculate CRC так:
Листинг 1.21. Использование глобальной переменной для определения длины пароля
for (a = 0; a <= length; a++)
В результате этих нехитрых преобразований мы получаем скорость в восемь миллионов паролей в секунду. Много? Подождите! Самое интересное еще только начинается...