
Техника Оптимизации Программ (фрагмент) 3/3
Шаг пятый. Удаление операции деления
Теперь на первое место вырывается функция gen_pswd, в которой процессор проводит более половины всего времени исполнения программы.
За gen_pswd с большим отрывом следуют функции Calculate CRC - ~21% и Check CRC - ~15%. Причем, ~40% от общего времени исполнения функции gen_pswd сосредоточено в одной-единственной "горячей" точке. Непорядок! Надо бы оптимизировать!
Двойной щелчок по высоченному прямоугольнику приводит нас к инструкции IDIV, выполняющий целочисленное деление. Постой, постой, а где у нас в gen_pswd целочисленное деление? А вот, уже нашли!
do_pswd(crypteddata, pswd, validCRC, 100*a/max_iter);
Здесь мы вычисляем процент проделанной работы. Забавно, но на это уходит приблизительно столько же времени, сколько и на саму работу! А раз так - ну все эти "градусники" к черту! Удаляем команду деления, подставляя вместо значения прогресса "0" или любое другое понравившееся вам число.
Перекомпилируем, и в результате получаем скорость в четырнадцать с половиной миллионов паролей в секунду!
Шаг шестой. Удаление мониторинга производительности
Несмотря на прямо-таки гигантскую скорость перебора, функция gen_pswd все еще оттягивает на себя ~22% времени исполнения программы, что не есть хорошо.
Двойной щелчок по ней показывает, что среди более или менее ровного ряда практически одинаковых по высоте диаграмм, возвышается всего лишь один красный прямоугольник. А ну-ка посмотрим что там!
Дизассемблирование позволяет установить, что за этой "горячей" точкой скрывается уже знакомая нам конструкция:
if (++x>66666)
{
x = 0;
printf("Current pswd : %10s [%d%%]\r",&pswd[0],progress);
}
Что ж! Во имя Ее Величества Производительности, мы решаемся полностью отказаться от мониторинга текущего состояния, и выбрасываем эти шесть строк напрочь.
В результате скорость перебора повышается еще на пять миллионов паролей в секунду. Хм, вообще-то не такая уж и большая прибавка, так что не факт, что такую оптимизацию следовало бы выполнять.
Шаг седьмой. Объединение функций
На этот раз самой "горячей" точкой становится сохранение регистра ESI где-то глубоко внутри функции Calculate CRC. Это компилятор "заботливо" бережет его содержимое от посторонних модификаций. Несмотря на то, что количество используемых переменных в программе довольно невелико и в принципе обращений к памяти можно было бы и избежать, разместив все переменные в регистрах, компилятор не в состоянии этого сделать, т. к. оптимизирует каждую функцию по отдельности.
Так давайте же, забыв про структурность, объединим все наиболее интенсивно используемые функции (gen_pswd, do_paswd, Check CRC и Calculate CRC) в одну "супер-функцию".
Ее реализация может выглядеть, например, так:
Листинг 1.22. Объединение функций gen_pswd, do_paswd, Check CRC и Calculate CRC в одну супер-функцию
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC)
{
int a, b, x;
int p = 0;
char *buff;
int length = strlen(pswd);
for(a = 0; a < max_iter; a++)
{
x = -1; for (b = 0; b <= length; b++) x += *(int *)((int)pswd + b);
if (x==validCRC)
{
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata); DeCrypt(pswd, buff);
printf("CRC %8X: try to decrypt: \"%s\"\n", validCRC,buff);
}
while((++pswd[p])>'z')
{
pswd[p] = '!'; p++; if (!pswd[p])
{
pswd[p]=' '; pswd[p+1]=0;length++;
}
}; p = 0;
}
return 0;
}
Компилируем, запускаем... ой! прямо не верим своим глазам - тридцать пять миллионов паролей в секунду! А ведь казалось, что резерв быстродействия уже исчерпан. Ну и кто теперь скажет, что Pentium - медленный процессор? Генерация очередного пароля, вычисление и проверка его контрольной суммы укладывается в каких-то двадцать тактов...
Двадцать тактов?! Хм! Тут еще есть над чем поработать!
Шаг восьмой. Сокращения операций обращение к памяти
Основная масса "горячих" точек теперь, как показывает профилировка, сосредоточена в цикле подсчета контрольной суммы пароля - на него приходится свыше 80% всего времени исполнения программы, из них 50% "съедает" условный переход, замыкающий цикл (Pentium-процессоры очень не любят коротких циклов и условных переходов), а остальные 50% расходуются на обращение к кэш-памяти. Тут уместно сделать небольшое пояснение.
Расхожее мнение утверждает, что чтение нерасщепленных данных, находящихся в кэш-памяти занимает всего один такт, - ровно столько же, сколько и чтение содержимого регистра. Это действительно так, но при более пристальном изучении проблемы выясняется, что "одна ячейка за такт", это пропускная способность кэш памяти, а полное время загрузки данных с учетом латентности составляет как минимум три такта. При чтении зависимых данных из кэша (как в нашем случае) полное время доступа к ячейке определяется не пропускной способностью, а его латентностью. К тому же, на процессорах семейства P6 установлено всего лишь одно устройство чтения данных и поэтому, даже при благоприятном стечении обстоятельств они могут загружать всего лишь одну ячейку за такт. Напротив, на данные, хранящиеся в регистрах, это ограничение не распространяется.
Таким образом, для увеличения производительности мы должны избавиться от цикла и до минимума сократить количество обращений к памяти. К сожалению, мы не можем эффективно развернуть цикл, поскольку нам заранее неизвестно количество его итераций. Аналогичная ситуация складывается и с переменными: программируя на ассемблере, мы запросто смогли бы разместить парольный буфер в регистрах общего назначения (благо 16-символьный пароль - самый длинный пароль, который реально найти перебором - размешается всего в четырех регистрах, а в остающихся трех регистрах располагаются все остальные переменные). Но для прикладных программистов, владеющих одним лишь языком высокого уровня, этот путь закрыт и им приходится искать другие решения.
И такие решения действительно есть! До сих пор мы увеличивали скорость выполнения программы за счет отказа от наиболее "тяжеловесных" операций, практически не меняя базовых вычислительных алгоритмов. Этот путь привел к колоссальному увеличению производительности, но сейчас он себя исчерпал и дальнейшая оптимизация возможна лишь на алгоритмическом уровне.
В алгоритмической же оптимизации нет и не может быть универсальных советов и общих решений, - каждый случай должен рассматриваться индивидуально, в контексте своего окружения. Возвращаясь к нашим баранам, задумаемся: а так ли необходимо считать контрольные суммы каждого нового пароля? В силу слабости используемого алгоритма подсчета CRC, его можно заменить другим, - более быстродействующим, но эквивалентным алгоритмом.
Действительно, поскольку младший байт пароля суммируется всего лишь один раз, то при переходе к следующему паролю его контрольная сумма в большинстве случаев увеличивается ровно на единицу. Именно "в большинстве" - потому, что при изменении второго и последующих байтов пароля, модифицируемый байт уже суммируется как минимум дважды, к тому же постоянно попадает то в один, то в другой разряд. Это немного усложняет наш алгоритм, но все же не оставляет его далеко впереди "тупой" методики постоянного подсчета контрольной суммы, используемой ранее.
Словом, финальная реализация улучшенного переборщика паролей может выглядеть так:
Листинг 1.23. Алгоритмическая оптимизация алгоритма просчета CRC
int gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC)
{
int a, b, x;
int p = 0;
char *buff;
int y=0;
int k;
int length = strlen(pswd);
int mask;
x = -1;
for (b = 0; b <= length; b++)
x += *(int *)((int)pswd + b);
for(a = 0; a < max_iter ; a++)
{
if (x==validCRC)
{
buff = (char *) malloc(strlen(crypteddata));
strcpy(buff, crypteddata); DeCrypt(pswd, buff);
printf("CRC %8X: try to decrypt: \"%s\"\n", validCRC,buff);
}
y = 1;
k = 'z'-'!';
while((++pswd[p])>'z')
{
pswd[p] = '!';
// следующий символ
y = y | y << 8;
x -= k;
k = k << 8;
k += ('z'-'!');
p++;
if (!pswd[p])
{
pswd[p]='!';
pswd[p+1]=0;
length++;
x = -1;
for (b = 0; b <= length; b++)
x += *(int *)((int)pswd + b);
y = 0;
pswd[p]=' ';
}
//printf("%x\n",y);
} // end while(pswd)
p = 0;
x+=y;
} // end for(a)
return 0;
}
Какой результат дала алгоритмическая оптимизация? Ни за что не догадаетесь - восемьдесят три миллиона паролей в секунду или ~1/10 пароля за такт. Фантастика!
И это при том, что программа написана на чистом Си! И ведь самое забавное, что хороший резерв производительности по-прежнему есть!
Шаг девятый. VTune - ваш персональный тренер
А теперь мы обратимся к наименее известному средству профилировщика VTune - Инструктору (в оригинале Coach так же переводимое как "тренер" или "учитель").
Фактически Инструктор - это ни что иное как высококлассный интерактивный оптимизатор, поддерживающий целый ряд языков: C, C++, Fortran и Java. Он анализирует исходный текст программы на предмет поиска "слабых" мест, а, обнаружив такие, дает подробные рекомендации по их устранению.
Разумеется, интеллектуальность Инструктора не идет ни в какое сравнение с сообразительностью живого программиста и вообще, как мы увидим в дальнейшем, Инструктор скорее туп, чем умен... и все-таки рассмотреть его поближе будет небесполезно.
Несмотря на то, что Инструктор в первую очередь ориентирован на программистов-новичков (на что указывает полностью "разжеванный" стиль подсказок), и для профессионалов он под час оказывается не лишним, особенно когда приходится оптимизировать чужой код, в котором лень досконально разбираться.
Плохая новость (впрочем, ее и следовало ожидать) - при отсутствии отладочной информации в профилируемой программе инструктор не может работать с исходным текстом и опускается на уровень чистого ассемблера (см. разд. "Шаг десятый. Заключительный"). Тем не менее, это обстоятельство не доставляет непреодолимых неудобств, т. к. текст программы именно анализируется, а не профилируется. Поэтому, пусть вас не смущает, что включение в исполняемый файл отладочной информации приводит к автоматическому "вырубанию" всех оптимизирующих опций компилятора. Инструктор, работая с исходным текстом программы, вообще не будет касаться скомпилированного машинного кода!
Итак, перекомпилируем наш демонстрационный пример, добавив ключ /Zi в командную строку компилятора и ключ /DEBIG - в командную строку линковщика. Загрузим полученный файл в VTune и, дождавшись появления диаграммы "Hot Spots", дважды щелкнем мышкой по самому высокому прямоугольнику, соответствующему, как мы уже знаем, функции gen_pswd, в которой программа проводит большую часть своего времени.
Теперь, удерживая левую клавишу мыши, выделяем тот фрагмент, который мы хотим проанализировать (логичнее всего выделить всю функцию gen_pswd целиком) и отыскиваем на панели инструментов такую довольно затейливую кнопку с изображением учителя, облаченного в красную рубаху, и коричневой ученической доски на заднем фоне. Нажмем ее. Инструктор запросит сведения о файле, которым компилировалась данная программа. На выбор предоставляется make-файл, файл препроцессора и, конечно же, как и во всякой профессиональной программе, возможность ручного ввода. Поскольку никаких особенных опций компиляции мы не задавали, а make-файла у нас все равно нет, мы выбираем "Manual Entry" и нажимаем кнопку OK. Пропускаем появившееся на экран ругательство - "No source option were specified" ("Исходные опции не были заданы") и жмем кнопку OK еще раз.
Профилировщик VTune тут же начнет анализ и буквально через несколько секунд не без удовлетворения сообщит: "There are 9 recommendations identified for the selected code. Double-Click on any advice for additional information" ("В выделенном коде распознано девять "рекомендательных шаблонов". Для получения дополнительной информации дважды щелкните по любому совету"). Оказывается, в нашей уже далеко "не хило" оптимизированной программе все еще присутствует, по меньшей мере, девять слабых мест! И не просто слабых, а настолько слабых, что они обнаруживаются тривиальным шаблонным поиском! Ну и мы и "молодцы", - нечего сказать!
Ладно, кончаем заниматься самобичеванием, а лучше посмотрим, что этот умник VTune тут нагородил. Рекомендации инструктора записаны прямо поверх кода программы и первое замечание, выглядит следующим образом:
84 for (b = 0; b <= length; b++) 85 x += *(int *)((int)pswd + b); The loop at line 84 can be unrolled 4 times .
"Цикл в строке 84 может быть развернут четыре раза". Глупый VTune! Этот цикл исполняется всего лишь раз за весь прогон программы и особой "погоды" его оптимизация не сделает! Кстати, а что такое "развертка циклов" и как ее осуществить? Дважды щелкаем по выделенной строке, и Инструктор имеет честь сообщить нам следующее:
Loop unrolling Examples: C, Fortran, Java* The loop contains instructions that do not allow efficient instruction scheduling and pairing. The instructions are few or have dependencies that provide little scope for the compiler to schedule them in such a manner as to make optimal use of the processor's multiple pipelines. As a result, extra clock cycles are needed to execute these instructions. Advice Unroll the loop as suggested by the coach. Create a loop that contains more instructions, but is executed fewer times. If the unrolling factor suggested by the coach is not appropriate, use an unrolling factor that is more appropriate. To unroll the loop, do the following: - Replicate the body of the loop the recommended number of times. - Adjust the index expressions to reference successive array elements. -Adjust the loop control statements. Result: - Increases the number of machine instructions generated inside the loop. - Provides more scope for the compiler to reorder and schedule instructions so that they pair and execute simultaneously in the processor's pipelines. - Executes the loop fewer times. Caution: Be aware that increasing the number of instructions within the loop also increases the register pressure.
В переводе на русский язык все вышесказанное будет звучать приблизительно таким образом:
Разворачивание цикла:
Данный цикл содержит инструкции, которые не могут быть эффективно спланированы и распараллелены процессором, поскольку они малочисленны [то бишь кворума мы здесь не наберем - КК] или содержат зависимости, что сужает возможности компилятора в их группировке для достижения наиболее оптимального использования конвейеров процессора. В результате, на выполнение этих инструкций расходуется значительно большее количество циклов.
Совет:
Разверните цикл, согласно советам "Учителя". Создайте цикл, такой чтобы он содержал больше инструкций, но исполнялся меньшее количество раз. Если степень развертки, рекомендуемая "Учителем", кажется вам неподходящей, используйте более подходящую степень.
Для развертки цикла сделайте следующее:
- Продублируйте тело цикла соответствующее количество раз;
- Скорректируйте ссылки на продублированные элементы массива;
- Скорректируйте условие цикла.
Результат:
- Увеличивается количество машинных инструкций внутри цикла;
- Появляется место, где "развернуться" компилятору для переупорядочивания и планирования потока инструкций так, чтобы они спаривались и выполнялись параллельно в конвейерах процессора.
- Выполнение цикла занимает меньшее время.
Предостережение:
Знайте, что увеличение количества инструкций в теле цикла влечет за собой увеличение "регистрового давления".
Согласитесь, весьма исчерпывающее руководство по развертке циклов! Причем, если вам все равно не понятно как именно разворачиваются циклы, можно кликнуть по ссылке "Examples" (примеры) и увидеть конкретный пример "продразверстки" на Си, Java или Fortran. Давайте выберем язык Си и посмотрим, что нам еще посоветует профилировщик VTune:
Original Code Optimized Code
for(i=0; i<n; i++) for(i=0; i<n-(n%3); i+=3)
a[i] = c[i] ; {
a[i] = c[i] ;
a[i+1] = c[i+1];
a[i+2] = c[i+2];
}
for(i;i < n; i++)
a[i] = c[i];
Тем не менее, мы этот цикл разворачивать не будем и пойдем дальше.
Совет номер два вновь рекомендует развернуть тот же самый цикл, но уже находящийся внутри цикла while. Поскольку, этот цикл получает управление лишь при удлинении перебираемого пароля на один символ (что происходит прямо-таки скажем не часто) он, как и предыдущий, не оказывает практически никакого влияния на производительность, а потому рекомендацию по его развороту мы отправим в /dev/null.
Совет номер три придирается к с виду безобидной конструкции p++, увеличивающий переменную p на единицу:
114 p++;
115 if (!pswd[p])
116 {
117 pswd[p]='!';
118 pswd[p+1]=0;
119 length++;
120 x = -1;
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
The loop whose index is incremented at line 114 should be interchanged with the loop whose index is incremented at line 121, for more efficient memory access
"Для достижения более эффективного доступа [к памяти] цикл, чей индекс увеличивается в строке 114, должен быть заменен циклом, чей индекс увеличивается в строке 121"?! Инструктор, судя по всему или "пьян", или от перегрева процессора слегка "спятил". Это вообще разные циклы. И индексы у них разные. И вообще они не имеют друг к другу никакого отношения, причем цикл, расположенный в строке 121, исполняется редко, так что совсем не понятно, что это профилировщик VTune к нему так пристал?!
Может быть, дополнительная информация от Инструктора все разъяснит? Дважды щелкаем по строке 114 и читаем:
Loop interchange: Loops with index variables referencing a multi-dimensional array are nested. The order in which the index variables are incremented causes out-of-sequence array referencing, resulting in many data cache misses. This increases the loop execution time. Advice: Do the following: - Change the sequence of the array dimensions in the array declaration. - Interchange the loop control statements. Result: The order in which the array elements are referenced is more sequential. Fewer data cache misses occur, significantly reducing the loop execution time.
Перестановка циклов:
Здесь наблюдается вложенные циклы с индексными переменными, обращающимися к многомерным массивам, Порядок, в котором увеличиваются индексные переменные, приводит к несвоевременному обращению к массивам, и как следствие этого - множественным кэш-промахам. В результате увеличивается время выполнения цикла.
Совет:
Сделайте следующее:
- Измените последовательность измерений массивов в их объявлении;
- Поменяйте местами "измерения" управления цикла [подразумевается: сделайте либо то, либо это, но ни в коем случае ни то и другое вместе - иначе "минус на минус даст плюс" и вы получите тот же самый результат - КК]
Результат:
Порядок, в котором обрабатываются элементы массива, станет более последовательным. Меньше кэш-промахов будет происходить, от чего время выполнения цикла значительно сократиться.
Какие многомерные массивы? Какие кэш-промахи? Здесь у нас и близко нет ни того, ни другого! Судя по всему, мы столкнулись с грубой ошибкой Инструктора (шаблонный поиск дает о себе знать!), но все же не поленимся, и заглянем в предлагаемый Инструктором пример, памятуя о том, что всегда в первую очередь следует искать ошибку у себя, а не у окружающих. Быть может, это мы чего-то недопонимаем...
Original Code Optimized Code
int b[200][120]; int b[200][120];
void xmpl17(int *a) void ympl17(int *a)
{ {
int i, j; int i, j;
int atemp;
for (i = 0; i
Ну вот, все правильно. Приводимый профилировщиком VTune фрагмент кода наглядно демонстрирует, что двухмерные массивы лучше обрабатывать по строкам, а не столбцам (см. "Часть III. Подсистема кэш-памяти"). Но ведь у нас нет двухмерных массивов, а - стало быть - и слушаться Инструктора в данном случае не надо.
Совет номер четыре и снова этот несчастный цикл подсчета контрольной суммы. Ну понравился он Инструктору - что поделаешь! Что же ему не понравилось на этот раз? Читаем...
121 for (b = 0; b <= length; b++)
122 x += *(int *)((int)pswd + b);
123 pswd[p]=' ';
124 y = 0;
125 }
126 } // end while(pswd)
Use the Intel C/C++ Compiler vectorizer to automatically generate highly
optimized SIMD code. The statement on line 122 and others like it will be
vectorized if the following program changes are made (double-click on any
line for more information):
==> Simplify the pointer expression to indicate contiguous array accesses.
==> Restructure the loop to isolate the statement or construct that
interferes with vectorization.
==> Try loop interchanging to obtain vector code in the innermost loop.
==> Simplify the pointer expression to indicate contiguous array accesses.
Используйте векторизатор компилятора Intel С/C++ для автоматической генерации высоко оптимизированного SIMD-кода. Оператор, находящийся в линии 122 и остальные подобные ему операторы, будут векторизованы при условии следующих изменений программы:
- Упростите выражение указателя для индикации смежных доступов к массиву;
- Реструктурируйте цикл для отделения выражения или логической конструкции, препятствующей векторизации;
- Попытайтесь перестроить цикл для получения векторного кода во вложенном цикле;
- Упростите выражение указателя для индикации смежных доступов к массиву;
Хорошие, однако, советы! А рекомендация упростить и без того примитивную форму адресации повторяется аж два раза! И это при том, что эффективно векторизовать данный цикл все равно не получится даже на Intel C/C++, а уж про все остальные компиляторы я и вовсе промолчу.
Тем не менее, все-таки заглянем за помощью - может быть, что-нибудь интересное скажут!?
Intel C++ Compiler Vectorizer The coach has identified an assignment or expression that is a candidate for SIMD technology code generation using Intel C++ Compiler vectorizer. Advice Use the Intel C++ Compiler vectorizer to automatically generate highly optimized SIMD code wherever appropriate in your application. Use the following syntax to invoke the vectorizer from the command line: prompt> icl -O2 -QxW myprog.cpp. The -QxW command enables vectorization of source code and provides access to other vectorization-related options. Result The Intel C++ Compiler vectorizer optimizes your application by processing data in parallel, using the Streaming SIMD Extensions of the Intel processors. Since the Streaming SIMD Extensions that the class library implements access and operate on 2, 4, 8, or 16 array elements at one time, the program executes much faster.
Векторизатор компилятора Intel C++
Инструктор идентифицировал присвоение или выражение, являющееся кандидатом для генерации кода по SIMD-технологии, используемой векторизатором компилятора Intel C++.
Совет:
Используйте векторизатор компилятора Intel C++ для автоматической генерации высоко оптимизированного SIMD-кода, подходящего к вашему приложению. Используйте следующий синтаксис для вызова векторизатора из командной строки: icl -O2 QxW myprog.cpp.
Ключ "-QxW" разрешает векторизацию исходного кода и предоставляет доступ к остальным векторным опциям.
Результат:
Векторизатор компилятора Intel C++ оптимизирует ваше приложение путем парализации обработки данных, с использованием поточного SIMD-расширения команд процессоров Intel. С тех пор как потоковые SIMD расширения библиотеки классов осуществляют доступ и обработку 2, 4, 8 или 16 элементов массива за один раз, скорость выполнения программы весьма значительно возрастает.
Бесспорно, векторизация - полезная штука, действительно позволяющая многократно увеличить скорость работы программы, но ее широкому внедрению в массы препятствует, по меньшей мере, два минуса: во-первых, подавляющее большинство x86-компиляторов не умеют векторизовать код, а переход на компилятор Intel не всегда приемлем. Во-вторых, векторизация будет по настоящему эффективна лишь в том случае, если программа изначально предназначалась под эту технологию. И хотя в мире "больших" машин векторизация кода известна уже давно, для x86-программистов это еще тот конек!
Совет номер пять или еще один просчет Инструктора. Так, посмотрим, что за перл выдал Инструктор на этот раз.
91 if (x==validCRC)
92 {
93 // копируем шифроданные во временный буфер
94 buff = (char *) malloc(strlen(crypteddata));
95 strcpy(buff, crypteddata);
96
97 // расшифровываем
98 DeCrypt(pswd, buff);
99
The argument list for the function call to _malloc on line 94 appears to be loop-invariant. If there are no conflicts with other variables in the loop, and if the function has no side effects and no external dependencies, move the call out of the loop.
(Список аргументов функции malloc, находящейся в строке 94, вероятно, инвариантен относительно цикла. Если это не вызовет конфликта с остальными переменными цикла, и если не будет иметь посторонних эффектов и внешних зависимостей, вынесите ее за пределы цикла).
Вообще-то, формально Инструктор прав. Вынос инвариантных функций из тела цикла - это хороший тон программирования, поскольку, находясь в теле цикла, функция вызывается множество раз, но, в силу своей независимости от параметров цикла, при каждом вызове она дает один и тот же результат. Действительно, не проще ли единожды выделив память при входе в функцию, просто сохранить возращенный указатель функции malloc в специальной переменной, а затем использовать его по мере необходимости?
Возражение номер один: ну и что мы в результате этого получим? Данная ветка вызывается лишь при совпадении контрольной суммы текущего перебираемого пароля с эталонной контрольной суммой, что происходит крайне редко - в лучшем случае несколько раз за все время выполнения программы.
Возражение номер два: перефразируя известный анекдот "я девушку кормил-поил, я ее и танцевать буду" можно сказать "та ветвь программы, которая выделила блок памяти, сама же его и освобождает, конечно, если это не приводит к неоправданному снижению производительности".
Таким образом, ничего за пределы цикла мы выносить не будем, что бы там нам не советовал Инструктор.
Совет номер шесть. Данный совет практически полностью повторяет предыдущий, однако, на этот раз, Инструктор посоветовал вынести за пределы цикла функцию De Crypt. Да, да! Счел ее инвариантом и посоветовал вынести куда подальше и это не смотря на то, что: а) код самой функции в принципе был в его распоряжении ("в принципе" потому, что мы приказали Инструктору анализировать только функцию gen_pswd). б) функции De Crypt передается указатель pswd, который явным образом изменяется в цикле! А раз так, то инвариантом функция De Crypt быть ну никак не может! И как только Инструктору не стыдно давать такие советы? Или все-таки стыдно - а вы думали почему он красный такой?
Совет номер семь. Сейчас Инструктор обращает наше внимание, на то, что: "The value returned by De Crypt() on line 98 is not used..." ("Значение, возвращаемое функцией De Crypt, расположенной в строке 98, не используется...") и дает следующий совет "If the return value is being ignored, write an alternate version of the function which returns void" ("Если возвращенное значение игнорируется, создайте альтернативную версию данной функции, возвращающей значение void").
В основе данного совета лежит допущение Инспектора, что функция, не возвращающая никакого значения, будет работать быстрее функции такое значение возвращающей. На самом же деле это более чем спорно. Возврат значения занимает не так уж много времени, и создание двух экземпляров одной функции реально обходится много дороже, чем накладные расходы на возврат никому не нужного значения.
Так что игнорируем этот совет и идем дальше.
Совет номер восемь. Теперь Инспектор принял за инвариант функцию printf, распечатывающую содержимое буфера buff, только что возвращенного функцией De Crypt. Мм... не ужели разработчикам профилировщика VTune было трудно заложить в "голову" Инспектора смысловое значение хотя бы основных библиотечных функций? Функция printf не зависимо от того является ли она инвариантом или нет, никогда не может быть вынесена за пределы цикла! И вряд ли стоит объяснять почему.
Совет номер девять. ...Значение, возвращаемое функций printf не используется, поэтому...
Что ж! Результатами такого инструктажа трудно остаться удовлетворенным. Из девяти советов мы не воспользовались ни одним, поскольку это все равно бы не увеличило скорость выполнения программы. Тем не менее, Инструктора не стоит считать совсем уж никчемным чукчей. Во всяком случае, он рассказывает о действительно интересных и эффективных приемах оптимизации, не все из которых известны новичкам.
Возможно мне возразят, что такая непроходимая тупость Инструктора объясняется тем, что мы подсунули ему уже до предела оптимизированную программу и ему ничего не осталось, как придираться к второстепенным мелочам. Хорошо, давайте напустим Инструктора на самый первый вариант программы, заставив его проанализировать весь код целиком. Он сделает нам 33 замечания, из которых полезных по-прежнему не окажется ни одного!
Шаг десятый. Заключительный
Все оставшиеся 17 "горячих" точек представляют собой издержки обращения к кэш-памяти и... штрафные такты ожидания за неудачную с точки зрения процессора группировку команд. Ладно, оставим обращения к памяти в стороне, вернее отдадим эту задачу на откуп неутомимым читателям (задумайтесь: зачем вообще теперь генерировать пароли, если их контрольная сумма считается без обращения к ним?) и займемся оптимальным планированием потока команд.
Обратимся к другому мощному средству профилировщика VTune - автоматическому оптимизатору, по праву носящему гордое имя "Assembly Coach" (Ассемблерный Тренер, - не путайте его с Инструктором!). Выделим, удерживая левую клавишу мыши, все тело функции gen_pswd и найдем на панели инструментов кнопку с изображением учителя (почему-то ярко-красного цвета), держащим указку на перевес. Нажмем ее.
На выбор нам предоставляется три варианта оптимизации, выбираемые в раскрывающимся списке Mode Of Operation, расположенном в верхнем левом углу:
- Automatic Optimization (Автоматическая оптимизация);
- Single Step Optimization (Пошаговая оптимизация);
- Interactive Optimization (Интерактивная оптимизация).
Первые два режима не представляют особого интереса, а вот качество Интерактивной оптимизации - выше всяческих похвал. Итак, выбираем интерактивную оптимизацию и нажимаем кнопку Next расположенную чуть правее раскрывающегося списка.
Содержимое экрана тут же преобразится (рис. 1.10) и на левой панели будет показан исходный ассемблерный код, а на правой - оптимизируемый код. В нижнем правом углу экрана по ходу оптимизации будут отображаться так называемые "assumption" (буквально - допущения), за разрешением которых оптимизатор будет обращаться к программисту. На рисунке в этом окне выведено следующее допущение:
Accept Offset Offset2 Assumption Description V 0x55 0x72 Instructions may reference the same memory
(Инструкции со смещениями 0x55 и 0x72 обращаются к одной и той же области памяти). Смотрим: что за инструкции расположены по таким смещениям. Ага:
1:55 mov ebp, DWORD PTR [esp+018h] 1:72 mov DWORD PTR [esp+010h], ecx
Несмотря на кажущиеся различия в операндах, на самом деле они адресуют одну и ту же переменную, т. к. между ними расположены две машинные команды PUSH, уменьшающие значение регистра ESP на 8. Таким образом, это предположение верно и мы подтверждаем его нажатием кнопки Apply, находящейся в верхней левой части экрана.
Теперь обратим внимание на инструкции, залитые красным цветом (на рисунке они с наиболее темной заливкой) и отмеченные красным огоньком светофора слева. Это отвратительно спланированные инструкции, обложенные "штрафными" тактами процессора.
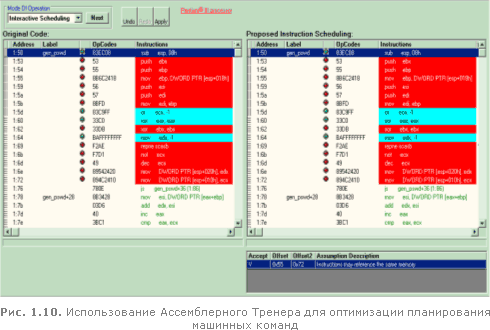
Давайте щелкнем по самому нижнему "светофору" и посмотрим, как профилировщик VTune перегруппирует наши команды... Ну вот, совсем другое дело! Теперь все инструкции залиты пастельным желтым цветом, что означает: никаких конфликтов и штрафных тактов нет. Что в оптимизированном коде изменилось? Ну, во-первых, теперь команды PUSH (заталкивающие регистры в стек) отделены от команды, модифицирующей регистр указатель вершины стека, что уничтожает паразитную зависимость по данным (действительно, нельзя заталкивать свежие данные в стек пока не известно положение его вершины).
Во-вторых, арифметические команды теперь равномерно перемешаны с командами записи/чтения регистров, поскольку вычислительное устройство (АЛУ - арифметико-логическое устройство) у процессоров Pentium всего одно, то эта мера практически удваивает производительность.
В-третьих, процессоры Pentium содержат только один полноценный x86 декодер и потому заявленная скорость декодирования три инструкции за такт достигается только при строго определенном следовании инструкцией. Инструкции, декодируемые только полноценным x86-декодером, следует размещать в начале каждого триплета, заполняя "хвост" триплета командами, которые "по зубам" остальным двум декодерам. Как легко убедиться, компилятор MS VC генерирует весьма неоптимальный с точки зрения Pentium-процессора код и профилировщик VTune перетасовывает его команды по-своему.
Листинг 1.24. Ассемблерный код, оптимизированный компилятором Microsoft Visual C++ 6.0 в режиме максимальной оптимизации (слева) и его усовершенствованный вариант, переработанный профилировщиком VTune (справа)
sub esp, 08h sub esp, 08h push ebx or ecx, -1 push ebp push ebx mov ebp, DWORD PTR [esp+018h] push ebp push esi mov ebp, DWORD PTR [esp+018h] push edi xor eax, eax mov edi, ebp push esi or ecx, -1 push edi xor eax, eax xor ebx, ebx xor ebx, ebx mov edx, -1 mov edx, -1 mov edi, ebp repne scasb repne scasb not ecx mov DWORD PTR [esp+020h], edx dec ecx not ecx mov DWORD PTR [esp+020h], edx dec ecx mov DWORD PTR [esp+010h], ecx mov DWORD PTR [esp+010h], ecx
Нажимаем еще раз кнопку Next и переходим к анализу следующего блока инструкций. Теперь профилировщик VTune устраняет зависимость по данным, разделяя команды чтения и сложения регистра ESI командой увеличение регистра EAX:
mov esi, DWORD PTR [eax+ebp] mov esi, DWORD PTR [eax+ebp] add edx, esi inc eax inc eax add edx, esi cmp eax, ecx cmp eax, ecx
Действуя таким образом, мы продолжаем до тех пор, пока весь код целиком не будет оптимизирован. И тут возникает новая проблема. Как это ни прискорбно, но профилировщик VTune не позволяет поместить оптимизированный код в исполняемый файл, видимо, полагая, что программист-ассемблерщик без труда перенаберет его с клавиатуры и вручную. Но мы то с вами не ассемблерщики! (В смысле: среди нас с вами есть и не ассемблерщики).
И потом - как прикажите "перебивать" код? Не резать же двоичный файл "в живую"? Конечно нет! Давайте поступим так (не самый лучший вариант, конечно, но ничего более умного мне в голову пока не пришло). Переместив курсор в панель оптимизированного кода в меню File, выберем пункт Print. В окне Field Selection (выбор полей) снимем флажки со всего, кроме Labels (метки) и Instructions (инструкции) и зададим печать в файл или буфер обмена.
Тем временем, подготовим ассемблерный листинг нашей программы, задав в командной строке компилятора ключ /FA (в других компиляторах этот ключ, разумеется, может быть и иным). В результате мы станем обладателями файла pswd.asm, который даже можно откомпилировать (ml /c /coff pswd.asm), слинковать (link /SUBSYSTEM:CONSLE pswd.obj LIBC.LIB) и запустить. Но что за черт! Мы получаем скорость всего ~65 миллионов паролей в секунду против 83 миллионов, которые получаются при оптимизации обычным путем. Оказывается, коварный MS VC просто не вставляет директивы выравнивания в ассемблерный текст! Это затрудняет оценку производительности качества оптимизации кода профилировщиком VTune. Ну да ладно, возьмем за основу данные 65 миллионов и посмотрим насколько VTune сможет улучшить этот результат.
Открываем файл, созданный профилировщиком и... еще одна проблема! Его синтаксис совершенно не совместим с синтаксисом популярных трансляторов ассемблера!
Листинг 1.25. Фрагмент ассемблерного файла, сгенерированного профилировщиком VTune
Label Instructions
gen_pswd sub esp, 08h
js gen_pswd+36 (1:86)
gen_pswd+28 mov esi, DWORD PTR [eax+ebp]
Во-первых, после меток не стоит знак двоеточия, во-вторых, в метках встречается запрещенный знак "плюс", в третьих, условные переходы содержат лишний адрес, заключенный в скобки на конце.
Словом нам предстоит много ручной работы, после которой "вычищенный" фрагмент программы будет выглядеть так:
Листинг 1.26. Исправленный фрагмент сгенерированного профилировщиком VTune файла стал пригоден к трансляции ассемблером TASM или MASM
Label Instructions
gen_pswd: sub esp, 08h
js gen_pswd+_36 (1:86)
gen_pswd+_28 mov esi, DWORD PTR [eax+ebp]
Остается заключить его в следующую "обвязку" и оттранслировать ассемблером TASM или MASM - это уже как вам больше нравится:
Листинг 1.27. "Обвязка" ассемблерного файла, в которую необходимо поместить оптимизированный код функции _gen_pswd, для его последующей трансляции
.386 .model FLAT PUBLIC _gen_pswd EXTERN _DeCrypt:PROC EXTRN _printf:NEAR EXTRN _malloc:NEAR _DATA SEGMENT my_string DB 'CRC %8X: try to decrypt: "%s"', 0aH, 00H _DATA ENDS _TEXT SEGMENT _gen_pswd PROC NEAS // код функции gen_pswd _gen_pswd ENDP _TEXT ENDS END
А в самой программе pswd.c функцию gen_pswd объявить как внешнюю. Это можно сделать например так:
Листинг 1.28. Объявление внешней функции gen_pswd в Си-программе
extern int _gen_pswd(char *crypteddata, char *pswd, int max_iter, int validCRC);
Теперь можно собирать наш проект воедино:
Листинг 1.29. Финальная сборка проекта pswd
ml /c /coff gen_pswd.asm cl /Ox pswd.c /link gen_pswd.obj
Прогон оптимизированной программы показывает, что она выдает ~78 миллионов паролей в секунду, что на ~20% чем было до оптимизации. Что ж! Профилировщик VTune весьма не слабо оптимизирует код! Тем не менее, полученный результат все же не дотягивает до скорости, достигнутой на предыдущем шаге. Конечно, камень преткновения не в профилировщике, а в компиляторе, но разве от этого нам легче?
Впрочем, на оптимизацию собственных ассемблерных программ эта проблема никак не отражается.
Итоги и прогнозы
Теперь самое время подвести итоги. Если откинуть первый неудачный вариант программы с постоянным вызовом функции printf, можно сказать, что мы увеличили скорость оптимизируемой программы с полутора до восьмидесяти четырех миллионов паролей в секунду, то есть без малого на два порядка! И у нас есть все основания этим гордиться! Пускай, мы далеко от теоретического предела и до исчерпания резерва производительности еще далеко (вот скажем, можно перебирать несколько паролей одновременно, использовать векторные MMX-команды) профилировка приложений, несомненно, лучшее средство избежать неоправданного снижения производительности!
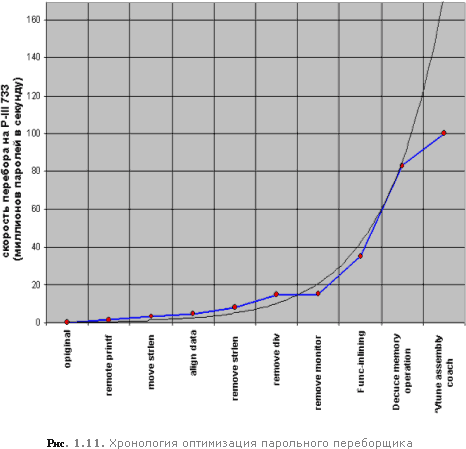
Любопытно, но каждый шаг оптимизации приводил к экспоненциальному росту производительности (рис. 1.11). Конечно, экспоненциальный рост наблюдается далеко не во всех случаях (можно сказать, что тут нам просто повезло), но, тем не менее, общая тенденция профилировки такова, что самые крупные "камни преткновения" по обыкновению находится "на глубине" и разглядеть их, не "окунувшись в воду" (в смысле в дебри кода) в общем-то, невозможно.
В этой главе мы рассмотрели лишь самые базовые средства профилировщика VTune (да и то мельком), но его возможности этим отнюдь не исчерпаются! Собственно это целый мир, содержащий помимо всего прочего собственный язык программирования и даже имеющий собственный интерфейс API, позволяющий вызывать функции VTune из своих программ (читай: "клепать" к профилировщику собственные плагины)...
Но, как бы то ни было, первый шаг в изучении профилировщика VTune уже сделан и в дальнейшем вы постепенно сможете осваивать его и самостоятельно. А напоследок рискну дать вам один совет. Пользоваться контекстовой помощью VTune крайне неудобно и множество разделов при этом так и остаются неохваченными. Поэтому, лучше воспользоваться любым help-декомпилятором и конвертировать hlp-файл в rtf, который затем можно открыть с помощью того же редактора Word и распечатать. Или, во всяком случае, - читать с экрана, ибо помощь занимает свыше трех тысяч страниц - бумаги не напасешься!
На этом вводную часть книги можно считать законченной.
Оглавоение
- Введение. Производительность - постановка проблемы. Пути повышения быстродействия программ. Обсуждение целесообразности оптимизации.
- Глава 0. Профилировка. Что такое профилировка, обзор современных профилировщиков, создание собственного профилировщика.
- Часть 1. Подсистема оперативной памяти. . В этой части рассказывается о принципе работы оперативной памяти, устройствах ее сопряжения с процессором и описываются приемы программирования, позволяющие разогнать память на максимальную производительность.
- Глава 1. Иерархия оперативной памяти. Короткий исторический очерк. Типы и уровни иерархии оперативной памяти (библиотеки управления памятью, менеджер куч, менеджер виртуальной памяти, процессор, кэш-контроллер, контроллер памяти, модули памяти).
- Глава 2. Устройство и принципы функционирования оперативной памяти. Устройство ядра памяти. Эволюция оперативной памяти: conventional DRAM (Page Mode DRAM) - "обычная" DRAM, эволюция динамической памяти, FPM DRAM (Fast Page Mode DRAM) быстрая страничная память, понятие "формулы памяти", EDO-DRAM (Extended Data Out) память с усовершенствованным выходом, BEDO (Burst EDO) - пакетная EDO RAM, SDRAM (Synchronous DRAM) - синхронная DRAM, DDR SDRAM, SDRAM II (Double Data Rate SDRAM) SDRAM с удвоенной скоростью передачи данных, RDRAM (Rambus DRAM) - Rambus-память. Сравнительная характеристика основных типов памяти.
- Глава 3. Взаимодействие памяти и процессора. Устройство типовых наборов системных логик (чипсетов). Типовая схема арбитража и обработки запросов. Узкие места некоторых моделей чипсетов. Вычисление полного времени доступа к памяти. Оптимизация работы с памятью.
- Глава 4. Назначение и устройство кэша. Понятие кэша. Краткий исторический очерк. Организация кэша. Понятие ассоциативности кэша. Политика записи. Двухуровневая организация кэширования. Раздельное хранение кода и данных. Буфера записи. Устройство и принципы функционирования кэш-подсистемы процессоров Pentium и Athlon. Архитектура и характеристики кэшей современных процессоров.
- Глава 5. Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность. Выравнивание данных. Упорядочивание структур данных. Использование упреждающего чтения. Использование преимуществ синхронного чтения. Упорядочивание обращения к памяти. Использование буферов записи.
- Глава 6. Управление кэшированием в x86 процессорах старших поколений. Кратный исторический экскурс. Программная предвыборка в процессорах K6+ и P-III+. Предвыборка в процессорах AMD K6++ и VIA C3. Предвыборка в процессорах P-III И P-4. Сводная характеристика инструкций предвыборки различных процессоров. Аппаратная предвыборка в микропроцессоре P-4.
- Глава 7. Практическое использование предвыборки. Определение предпочтительной кэш-иерархии. Планирование дистанции предвыборки. Увеличение эффективности предвыборки. Оптимизация структур данных под аппаратную предвыборку.
- Глава 8. Секреты копирования памяти или практическое применение новых команд процессоров PENTIUM-III и PENTIUM-4. Оптимизация типовых операций с памятью: Оптимизация копирования памяти. Оптимизация заполнения (инициализации) памяти.
- Часть 2. Сравнительный анализ оптимизирующих компиляторов языка Си\Си++. В этой части планируется рассказать о методах автоматической оптимизации и сравнить эффективность машинной и ручной кодогенерации.
- Глава 8. Основные методы оптимизации, используемые компиляторами: Оптимизация константных выражений. Замена переменных константными значениями ("размножение" констант). Вычисление значения переменных на стадии компиляции ("свертка" констант). Вычисление значений функций на стадии компиляции ("свертка" функций). Оптимизация алгебраических выражений. Удаление неиспользуемых переменных. Удаление копий переменных. Удаление неиспользуемых присвоений. Удаление лишних выражений. Удаление лишних вызовов функций. Выполнение алгебраических упрощений. Оптимизация подвыражений. Оптимизация арифметических операций. Оптимизация ветвлений. Замена условных переходов арифметическими операциями. Удаление лишних условий. Удаление заведомо ложных условий. Оптимизация switch. Балансировка логического древа. Создание таблиц переходов. Оптимизация циклов. Оптимизация вызова функций. Оптимизация передачи аргументов. Оптимизация пролога/эпилога функций. Оптимизация распределения переменных. Оптимизация инициализации строк. Оптимизация "мертвого" кода. Оптимизация константных условий.
- Глава 9. Смертельная схватка: ассемблер vs. компилятор. Краткий экскурс в историю или ассемблер - это всегда весна. Критерии оценки качества машинной оптимизации. Методики оценки качества машинной оптимизации. Сравнительный анализ основных компиляторов. Обсуждение результатов тестирования. Наглядная демонстрация качества машинной оптимизации. Определение ситуаций предпочтительного использования ассемблера. Особое замечание о создании защитного кода на ассемблере. Программирование на ассемблере как особый род творчества.
- Часть 3. Приложения
- Предметный указатель
- Глоссарий
- Предметный указатель