
Как сохранять таблицы Microsoft Office в формате HTML
Постановка задачи
Одна из самых распространенных форм представления информации на Web-страницах — всевозможные таблицы. Особенно часто такие конструкции используются, когда требуется регулярно обновлять информацию. Поскольку таблица — элемент категории block-level, ее достаточно просто заменять, не нарушая общий дизайн страницы.
Но таблицы удобны не только для отображения информации, но и для ее хранения и обработки. Часто источником данных для Web-страниц служат классические приложения Microsoft Office — Word и Excel, обладающие мощными средствами обработки данных. В таких случаях приходится экспортировать таблицы Microsoft Office в таблицы HTML, и, естественно, возникает желание такой экспорт автоматизировать.
Стандартные средства формирования кодов HTML, имеющиеся в Microsoft Office, для профессионального применения не годятся — прежде всего из-за своей избыточности. Эти средства с определенной натяжкой еще можно использовать для первичного формирования страниц, но уж никак не для обновления существующих, хорошо отформатированных документов. В таких документах никакие элементы оформления не требуются, необходимо только воспроизводить структуру и содержание таблиц; а сохранение таких документов заново как Web-страниц средствами Microsoft Office только испортит их, опять добавив избыточные элементы форматирования, от которых с таким трудом избавляются Web-мастеры.
Уточним требования к программе, которой мы будем пользоваться для создания HTML-документов с таблицами. Пусть исходные данные — это таблицы, созданные в одном из приложений Microsoft Office. Структура таблиц может быть произвольной; допускается любое разумное объединение ячеек. Слово "разумное" в данном контексте означает, что таблица изначально была регулярной (свойство Uniform) и к ней применялись операции объединения ячеек. В этом случае таблица будет иметь эквивалентное представление в виде совокупности элементов
<TR> и <TD>В Excel любая таблица удовлетворяет этим требованиям, а вот в Word — нет. Таблицы Word допускают перемещение границ ячеек в отдельных строках, что в HTML реализуется только в виде отдельной таблицы. Это следует четко осознавать и по возможности в Word не использовать. Как поступать со случайно деструктурированными таблицами Word, будет показано ниже.
В ячейках исходной таблицы могут быть любые элементы, предусмотренные HTML: текст и inline-элементы, с соответствующими тэгами, включая вызовы функций JavaScript.
Результат преобразования — код HTML — необходимо поместить в произвольно заданные места существующего HTML-документа (прототипа). Если исходная таблица велика, что имеет место при работе со списками, целесообразно предусмотреть разбиение таких таблиц на разделы. Чтобы уж совсем усложнить задачу, потребуем пакетной обработки множества различных таблиц.
Экспорт отдельной таблицы Excel
Первый шаг в решении поставленной задачи — разработка процедуры, выполняющей экспорт отдельной таблицы. В качестве источника данных выберем таблицу, помещенную на листе Excel. Таблицы Excel гораздо предпочтительнее таблиц Word и не только потому, что имеют множество встроенных функций. Таблицы Word очень легко незаметно для пользователя деструктурировать: для этого достаточно сдвинуть боковые границы отдельных ячеек по отношению к границам столбцов. В этом случае возникает проблема, как интерпретировать смещенные ячейки. Стандартные процедуры Word при экспорте всегда разбивают такие конструкции на отдельные таблицы, даже если визуально это смещение в документе Word незаметно. Альтернативное решение, "исправляющее" таблицы Word, мы приведем ниже. В таблицах же Excel подобное невозможно. Ячейки можно объединять, но при этом границы столбцов и строк всегда остаются неизменными для всей таблицы.
Помня, что экспорт отдельной таблицы не самоцель, а лишь часть общей задачи, выберем в качестве исходных данных для процедуры объект Range, передаваемый в качестве параметра, или объект Selection. Результат преобразования — строки кода HTML — будем выводить в некий текстовый файл с помощью инструкции Print #.
Нам понадобятся строковые константы, задающие тэги HTML. В зависимости от потребностей пользователя эти константы должны содержать параметры необходимых стилей, выбранных для оформления страницы:
|
Как видно из приведенного описания, для тэга
<TR>предусмотрено два стиля, что позволит по-разному оформлять четные и нечетные строки таблицы.
Сама процедура экспорта таблицы приведена ниже. Единственную сложность в ней представляет анализ объединения ячеек. Выходной файл имеет номер 2 (номер 1 зарезервирован для входного файла — прототипа страницы).
|
Экспорт совокупности таблиц
Важный частный случай экспорта таблиц — экспорт списков; такие списки необходимо разделять на группы. Современный способ группировки информации — динамические окна (nuggets), допускающие свертывание и развертывание. Конструктивно nugget состоит из двух частей: заголовка с кнопкой maximize/ minimize и тела, помещенного в контейнер
<DIV>Тело — это отдельная таблица, преобразовывать которую мы уже научились. Теперь, если на исходном листе Excel создать список и разделить его на группы, добавив строки заголовков, отличающиеся форматом или специальным признаком, можно сгенерировать совокупность nuggets. Прежде всего нам понадобятся дополнительные константы, задающие необходимые тэги.
|
Здесь необходимы некоторые пояснения. В некоторых выражениях можно заметить служебные слова VALUE и COUNT, написанные прописными буквами. Эти слова указывают место вставки переменных значений, вычисляемых по ходу обработки списка. Вставка выполняется с помощью функции замены вхождений подстроки в строковое выражение. В Visual Basic for Applications версии Office 2000 такая функция существует и называется Replace. Для совместимости с Microsoft Office 97 применяется пользовательская функция ReplaceString, выполняющая те же действия.
Так же, как и в процедуре преобразования отдельной таблицы, в данном случае предусмотрены два стиля оформления тела: для четных и нечетных nuggets. Полный текст макроса, осуществляющего экспорт списка в виде совокупности таблиц, заключенных в тела nuggets, приведен ниже. Предполагается, что заголовки разделов выполнены полужирным шрифтом, а первый столбец списка используется для нумерации групп.
|
В приведенном макросе используются две вспомогательные процедуры — для формирования заголовка и тела nuggets соответственно. Эти процедуры достаточно просты и в специальных комментариях не нуждаются.
|
Отображение кодов HTML в исходном документе
В предыдущих разделах приведены способы формирования HTML-кодов для отдельной таблицы и для списка, порождающего множество таблиц, разделенных на группы. В качестве заполнителя пространства между тэгами
<TD> и </TD>используется свойство VALUE (тип данных VARIANT) соответствующих ячеек исходного листа Excel. Никакого анализа содержимого ячеек не проводится. Это позволяет удовлетворять требованиям универсальности. В ячейки исходных таблиц, наряду с текстом, числами и формулами, можно поместить произвольные фрагменты HTML-кода, обеспечивая тем самым любые желаемые последствия. Например, можно вставить гиперссылки с параметром target, графические элементы, указать стили или функции JavaScript.
К сожалению, за такую универсальность приходится расплачиваться совершенно неприглядным внешним видом исходного документа. Представьте себе, что в фирменном прайс-листе, в колонке со ссылкой "Buy Now!" окажется длиннющий HTML-код. Такую таблицу не то что напечатать — показать кому-либо страшно.
Естественное решение этой проблемы — заимствовать у гипертекстовых документов две формы представления информации: внешнюю, отображаемую браузером, и внутреннюю — в виде кода HTML. Конечно, вряд ли разумно строить интерпретатор для всех тэгов языка, достаточно ограничиться некоторым замещающим текстом. Строго говоря, для ячеек таблицы, наряду со свойствами VALUE, FORMULA, TEXT, следовало бы доопределить свойство HTML. Однако необходимость обеспечить ввод информации вручную диктует совсем не объектно-ориентированное решение. Это решение сводится к созданию обычной пользовательской функции, одним из параметров которой будет переменная, задающая форму вывода результата — замещающий текст, нужный для отображения ячеек при работе в Excel, или HTML-код, использующийся при экспорте. Другой параметр проектируемой функции также очевиден. Это строка — прототип кода HTML. Здесь мы воспользуемся тем же приемом с замещением, который был применен в процедурах со вставкой идентификаторов при формировании nuggets. В прототипе следует указать позиции подстановки переменных значений с помощью специальных уникальных кодов.
Чтобы сделать функцию универсальной, предусмотрим переменное число параметров, каждый из которых будет размещаться в заданных позициях строки-прототипа. В качестве специальных кодов прототипа можно использовать порядковый номер элемента в массиве параметров. Перед этим номером в прототипе необходимо поместить специальную строку — тэг, отличающий идентификатор подстановки от прочих комбинаций символов в коде HTML. Что касается строки замещения, то пусть ее роль выполняет первый элемент массива. С учетом сказанного текст новой пользовательской функции выглядит следующим образом.
|
Результаты работы приведенной функции показаны на рисунке. В первой строке списка выводу подлежала строка замещения. Это состояние соответствует параметру blnHTML = 0. Во второй строке выведен весь HTML-код с произведенной подстановкой шести параметров. В этом случае blnHTML = 1. В третьей строке показана сама формула в режиме редактирования. В качестве тэга перед номером параметра в прототипе использован символ "#".
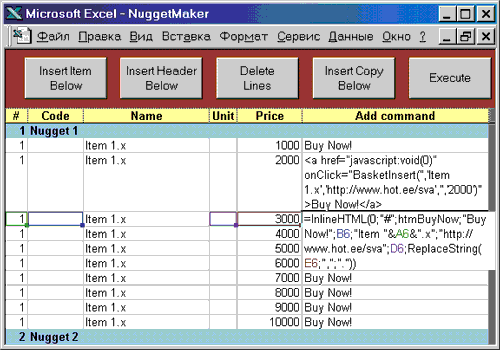
Два варианта отображения исходных данных в таблице Excel.
К сожалению, одной этой функции недостаточно. В процессе экспорта таблиц необходимо проверять, имеется ли в текущей ячейке такая формула, а если имеется, то необходимо переключиться в режим отображения HTML, извлечь код, а затем переключиться в "нормальный" режим отображения.
Эти действия выполняет вспомогательная функция, приведенная ниже:
|
Теперь, чтобы все функции работали вместе, необходимо в процедурах предыдущих примеров заменить в инструкциях Print # операнды получения свойств вида:
Объектная_переменная.VALUE
на функцию вида:
ReplaceValue(Объектная_переменная)
Использование прототипа Web-страницы
Приведенных выше процедур достаточно, чтобы сформировать законченные фрагменты HTML-кода. Осталось вставить их в нужное место Web-страницы. Для этого потребуется исходный HTML документ — прототип и операции ввода-вывода текстовых файлов.
Что касается прототипа, то его следует подготовить традиционными средствами, например, с помощью FrontPage, отметив специальным образом места для вставки необходимых таблиц. Как сделать такие отметки? Воспользуемся способом, применяемым в профессиональной серверной технологии PHP. В позициях, где должна будет появиться таблица, поместим тэги вида
<?php … ?>(конечно, ради приличия, следует заменить префикс php, например, на vba). Присутствие таких тэгов в обычном HTML-документе никак не сказывается на отображении страниц любым браузером. Страницы можно спокойно проектировать и отлаживать, сообщений об ошибках не последует. Тэги php всегда остаются невидимыми. Внутри такого тэга можно поместить любое указание препроцессору, роль которого в нашем случае будет выполнять Visual Basic for Applications. Если, например, тэг
<?vba include="List1" ?>обозначает необходимость вставки всех таблиц, расположенных на листе с именем List1 рабочей книги Excel, то, включая его в создаваемый HTML-код прототипа, можно разместить в прототипе указания по формированию кодов для таблиц или списков из различных листов и даже различных документов, созданных средствами Microsoft Office.
На этом подготовку прототипа можно считать законченной и переходить непосредственно к вводу-выводу.
Необходимо заметить, что хотя практически во всех приложениях Microsoft Office имеются стандартные диалоги открытия и сохранения файлов, для работы с файлами формата HTML удобнее пользоваться элементом управления ActiveX — Microsoft Common Dialog Control (COMDLG32.OCX). Программирование в этом случае проще, а окно диалога не содержит "лишних" возможностей.
Окончательный алгоритм работы макроса формирования HTML-документа выглядит следующим образом. Сначала выводится диалог открытия файла-прототипа для чтения. Затем выводится диалог для сохранения файла результата. Файл-прототип читается построчно и копируется в выходной файл. Процесс продолжается до тех пор, пока во входном потоке не встретится тэг вида
<?vba include="SheetName" ?>
В этом случае активизируется указанный лист и выполняется приведенная выше процедура ListLoop. Эта процедура генерирует необходимые строки в выходном потоке. Сам тэг
<?vba..>в выходной файл не переписывается. По окончании работы ListLoop выбирается следующая строка из входного потока, которая либо просто копируется в выходной файл, либо снова инициирует экспорт информации уже из другого листа книги. Процесс повторяется до конца входного файла. Затем файлы закрываются.
Эта простенькая заключительная процедура, большую часть которой составляют операторы фиксации ошибок при открытии текстовых файлов, приведена ниже:
|
Таблицы в документах Word
Безусловно, при необходимости профессионально работать с таблицами лучше выбирать Excel. Однако на практике встречаются случаи использования таблиц в документах Word. Некоторое время назад к автору обратилась одна солидная фирма, специализирующаяся на организации обучения иностранным языкам за границей. При создании сайта у них возникла проблема с переносом накопленной информации на Web страницы. Исходная информация — а это были обширные таблицы с расписаниями курсов — содержалась в документах Word. Таблицы имели объединенные ячейки, как по столбцам, так и по строкам. Было очевидно, что с таблицами продолжительное время активно работали, в результате чего их внутренняя структура была полностью разрушена, хотя визуально и при печати таблицы выглядели вполне нормально. Неприятности начинались только при попытках копирования таблиц в другие приложения — FrontPage или Excel — и при попытках сохранять документы в формате HTML. Так, для одной-единственной таблицы Word'97 формировал HTML-документ размером 25 Кбайт; при этом страница в браузере мало напоминала оригинал в Word. Word 2000 справлялся с задачей лучше: результат преобразования больше походил на источник, зато размер HTML-файла становился просто фантастическим — более 100 Кбайт(!) Положение казалось безвыходным, так как таблиц было много, а сроки создания сайта поджимали.
Проблемы были разрешены с помощью небольшого макроса, который формировал HTML-документ размером всего 5 Кбайт, и этот документ полностью удовлетворял требованиям заказчика.
Для решения задачи был применен эвристический подход, который может оказаться весьма полезным при работе с любыми таблицами Word. Суть алгоритма такова — прежде всего определяется максимальная размерность объекта Table. Далее в оперативной памяти создается двумерный массив той же размерности, что и таблица. Этот массив инициализируется специальными значениями, обозначающими свободные ячейки:
|
После подготовки массива проводится "зондирование" исходной таблицы с попыткой извлечь содержимое каждой ячейки. Если ячейки с определенными координатами не существует, возникает ошибка, а соответствующий элемент массива остается неизменным:
|
В результате проделанной операции исходная таблица попросту переписывается в массив. При этом таблица приводится к регулярному виду, известному как свойство Uniform = True. На первый взгляд, в приведенном фрагменте нет ничего примечательного. Но если присмотреться, то можно отметить очень любопытную деталь. Несмотря на то, что зондируется ячейка с координатами intRow и intCol, извлекаемый текст записывается в элемент массива с другими координатами! Эти координаты цели извлекаются из свойств RowIndex и ColumnIndex. Такая особенность объектной модели Word проявляется только при объединении ячеек; для таблицы Uniform координаты совпадают.
Непосредственно HTML-код генерируется уже на основе заполненного регулярного массива, построчно. Параметры ROWSPAN и COLSPAN формируются путем подсчета "пустых" ячеек справа и вниз от текущей позиции:
|
Оставить комментарий
Комментарии


avzhur
avzhur@mail.ru