
Web Основы с LWP
Web Основы с LWP
Введение
LWP (сокращение от "Library for WWW in Perl") это очень популярная группа модулей языка Perl для доступа к данным в сети Internet. Как и большинство модулей языка Perl, на каждый модуль из состава LWP присутствует документация с полным описанием его интерфейса. Однако, в LWP есть множество модулей, для которых довольно сложно найти документацию по, казалось бы, простейшим вещам.
Введение в использование LWP, очевидно, должно занять целую книгу, -- книгу, которая только вышла из печати, и названную: Perl & LWP. Эта статья предлагает Вам несколько примеров, которые помогут Вам в организации обычных вещей с LWP.
Доступ к страничкам с помощью LWP::Simple
Если Вы всего лишь хотите получить
документ, находящийся по определённому адресу(URL), то самый простой способ
сделать это - использовать функции модуля LWP::Simple.
В Perl-скрипте Вы можете сделать
это, вызвав функцию get($url). Она попытается вытянуть содержимое
этого URL. Если всё отработает нормально, то функция вернёт это содержимое;
но если произойдёт какая-нибудь ошибка, то она вернёт undef.
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current';
# Всего лишь для примера: новые записи на /Fresh Air/
use LWP::Simple;
my $content = get $url;
die "Couldn't get $url" unless defined $content;
# Далее что-нибудь делаем с $content, например:
if($content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
Более удобный вариант функции get
- это getprint, который удобен для простмотра содаржимого страниц
через Perl. Если функция getprint может "достать" страничку, адрес
которой Вы задали, то она отправляет содержимое в STDOUT; в противном
случае, в роли жалобной книги выступает STDERR.
% perl -MLWP::Simple -e "getprint 'http://cpan.org/RECENT'"
Это URL простого текстового файла.
В нём содержится список новых файлов на CPAN за последние две недели. Вы легко
можете сделать shell-команду, которая, например, будет высылать Вам список новых
модулей Acme:::
% perl -MLWP::Simple -e "getprint 'http://cpan.org/RECENT'" \
| grep "/by-module/Acme" | mail -s "New Acme modules! Joy!" $USER
В модуле LWP::Simple
существует ещё несколько довольно полезных функций, включая функцию для выполнения
HEAD-запроса для URL (полезна для проверки ссылок или получения
даты последней корректировки документа) и две функции для сохранения и зеркалирования
URL в локальный файл. Смотрите документацию
по LWP::Simple для более детальной информации, или Главу 2, "Web Основ"
Perl & LWP для большего количества примеров.
Основы классовой модели LWP
Функции LWP::Simple
удобны только для простых случаев, но эти функции не поддерживают теневых посылок(далее
cookies) и проверки подлинности(далее authorization); Они также не позволяют
устанавливать какие-либо параметры HTTP запроса; и главное, они не позволяют
считывать строки заголовка в HTTP ответе (особенно полный текст сообщения в
случае HTTP ошибки( HTTP error message)). Для доступа ко всем этим возможностям,
Вы должны использовать весь набор классов LWP.
LWP содержит множество классов,
но главные два, которые Вы должны понимать - это LWP::UserAgent
и HTTP::Response. LWP::UserAgent это класс для "виртуальных
броузеров", кторыми Вы будете пользоваться для выполнения запросов. HTTP::Response
это класс для ответов (или сообщений об ошибке), которые Вы получаете обратно,
после запроса.
Основное выражение при работе с
LWP: $response = $browser->get($url), или полностью:
use LWP 5.64; # Загружаем все нужные LWP классы, и удостовериваемся
# в достаточной свежести версии модуля.
my $browser = LWP::UserAgent->new;
...
# Используется ниже, тот URL, которому и будет сделан запрос:
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current';
my $response = $browser->get( $url );
die "Can't get $url -- ", $response->status_line
unless $response->is_success;
die "Hey, I was expecting HTML, not ", $response->content_type
unless $response->content_type eq 'text/html';
# или другой content-type, который Вам подходит
# В противном случае, производим обработку содержимого:
if($response->content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
$browser, который содержит объект
класса LWP::UserAgent, и объект $response, который из
класса HTTP::Response. Обычно Вам надо не более одного объекта $browser;
но каждый раз как Вы делаете запрос, Вы получаете назад новый объект HTTP::Response,
который содержит несколько интересных методов:
-
Status code(Код состояния), который показывает успех либо неудачу запроса (Вы это можете проверить так:
$response->is_success). -
HTTP status line(строка состояния), которая, я думаю, будет довольна информативна в случае ошибки (её Вы можете увидеть, используя
$response->status_line, она возвращает что-то вроде: "404 Not Found"). -
MIME content-type, например "text/html", "image/gif", "application/xml", и т.д., который Вы можете увидеть, используя
$response->content_type -
Собственно содержимое запрашиваемого документа в
$response->content. В случае с HTML, здесь будет HTML код; если - GIF, то$response->contentвернёт бинарные данные GIF. -
А также множество удобных и более специфических, которые описаны в документации по
HTTP::Response, и его суперклассам,HTTP::MessageиHTTP::Headers.
Добавление других заголовков HTTP запроса
Вот наиболее часто используемый
синтаксис для запросов $response = $browser->get($url), но,
честно говоря, Вы можете добавлять собственные строки HTTP заголовков к запросу,
добавлением списка пар ключ-значение после URL, например:
$response = $browser->get( $url, $key1, $value1, $key2, $value2, ... );
Вот как отправить Netscape-подобные заголовки:
my @ns_headers = (
'User-Agent' => 'Mozilla/4.76 [en] (Win98; U)',
'Accept' => 'image/gif, image/x-xbitmap, image/jpeg,
image/pjpeg, image/png, */*',
'Accept-Charset' => 'iso-8859-1,*,utf-8',
'Accept-Language' => 'en-US',
);
...
$response = $browser->get($url, @ns_headers);
Если Вы не будете использовать этот массив в дальнейшем, Вы можете поступить следующим образом:
$response = $browser->get($url,
'User-Agent' => 'Mozilla/4.76 [en] (Win98; U)',
'Accept' => 'image/gif, image/x-xbitmap, image/jpeg,
image/pjpeg, image/png, */*',
'Accept-Charset' => 'iso-8859-1,*,utf-8',
'Accept-Language' => 'en-US',
);
Если Вы собираетесь изменить только
'User-Agent'-параметры, Вы можете изменить стандартную установку объекта $browser
"libwww-perl/5.65" (или что-то подобное) на всё что Вы хотите, используя соответствующий
метод объекта LWP::UserAgent:
$browser->agent('Mozilla/4.76 [en] (Win98; U)');
Включение Cookies(Теневых посылок)
Обычно объект LWP::UserAgent
работает как броузер с отключённой поддержкой cookies. Существует несколько
путей для того, чтобы включить такую поддержку, используя метод cookie_jar.
"cookie jar" - это объект, который, если можно так сказать, олицетворяет собой
маленькую БД со всеми HTTP cookies, о которых может знать броузер. "БД" может
быть сохранена на диск (так работает Netscape, используя файл cookies.txt),
или "висеть" в памяти, при этом весь набор cookies будет потерян, как только
программа завершит свою работу.
Для того, чтобы создать пустой объект
cookie jar в памяти, вызовите cookie_jar метод следующим образом:
$browser->cookie_jar({});
Для того, чтобы делать копии cookies
в файл на диске, который будет содержать весь набор cookies, с которыми работал
броузер, после завершения программы, вызовите cookie_jar метод
следующим образом:
use HTTP::Cookies;
$browser->cookie_jar( HTTP::Cookies->new(
'file' => '/some/where/cookies.lwp',
#файл обмена
'autosave' => 1,
#по завершении, сохранять ли файл
));
Этот файл будет в специфическом
формате LWP. Если Вы хотите получить доступ к cookies из вашего Netscape-cookies
файла, Вы можете использовать следующий метод: HTTP::Cookies::Netscape:
use HTTP::Cookies;
$browser->cookie_jar( HTTP::Cookies::Netscape->new(
'file' => 'c:/Program Files/Netscape/Users/DIR-NAME-HERE/cookies.txt',
# откуда читать куки
));
Вы можете добавить строку 'autosave'
=> 1 , как мы делали ранее, но в момент записи существует вероятность
того, что Netscape может отказать в записи некоторых cookies обратно на диск.
Отправка данных форм методом POST
Многие HTML формы отправляют данные на сервер, используя запрос HTTP POST, который вы можете осуществить следующим образом:
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
);
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
headerkey1 => value1,
headerkey2 => value2,
);
Например, следующая программа осуществляет поисковый запрос на AltaVista (отправкой некоторых данных форм, используя метод HTTP POST), и извлекает из теста ответа количество совпадений:
use strict;
use warnings;
use LWP 5.64;
my $browser = LWP::UserAgent->new;
my $word = 'tarragon';
my $url = 'http://www.altavista.com/sites/search/web';
my $response = $browser->post( $url,
[ 'q' => $word, #поисковая фраза
'pg' => 'q', 'avkw' => 'tgz', 'kl' => 'XX',
]
);
die "$url error: ", $response->status_line
unless $response->is_success;
die "Weird content type at $url -- ", $response->content_type
unless $response->content_type eq 'text/html';
if( $response->content =~ m{AltaVista found ([0-9,]+) results} ) {
#Подстрока будет вида: "AltaVista found 2,345 results"
print "$word: $1\n";
} else {
print "Couldn't find the match-string in the response\n";
}
Передача данных форм методом GET
Некоторые HTML формы передают данные
не отправкой методом POST, а совершением обыкновенного GET запроса
с определённым набором данных в конце URL. Например, если Вы пойдёте на imdb.com и запустите поиск по фразе
Blade Runner, то URL, который Вы увидите, будет следующим:
http://us.imdb.com/Tsearch?title=Blade%20Runner&restrict=Movies+and+TV
Для запуска такого поиска при помощи LWP, надо сделать следующее:
use URI;
my $url = URI->new( 'http://us.imdb.com/Tsearch' );
# создаёт объект, представляющий URL
$url->query_form( # Здесь пары ключ => значение:
'title' => 'Blade Runner',
'restrict' => 'Movies and TV',
);
my $response = $browser->get($url);
Смотрите Главу 2, "Формы" книги Perl & LWP для более подробного изучения HTML форм, также как и главы с шестой по девятую для подробного изучения извлечения данных из HTML.
Преобразование относительных в абсолютые ссылки
URI класс, который мы рассмотрели
только что, предоставляет множество всевозможных функций для работы с различными
частями URL (такие как определение типа URL - $url->scheme,
определение на какой хост он ссылается - $url->host, , и так
далее на основании документации по классам
URI. Тем не менее, наиболее интересными являются метод query_form,
рассмотренный ранее, и теперь метод new_abs для преобразования
относительной ссылки("../foo.html") в абсолютную("http://www.perl.com/stuff/foo.html"):
use URI;
$abs = URI->new_abs($maybe_relative, $base);
Например, рассмотрим эту программку, которая выбирает ссылки из HTML-странички сновыми модулями на CPAN:
use strict;
use warnings;
use LWP 5.64;
my $browser = LWP::UserAgent->new;
my $url = 'http://www.cpan.org/RECENT.html';
my $response = $browser->get($url);
die "Can't get $url -- ", $response->status_line
unless $response->is_success;
my $html = $response->content;
while( $html =~ m/<A HREF=\"(.*?)\"/g ) {
print "$1\n";
}
При запуске она начинает выдавать что-то вроде этого:
MIRRORING.FROM
RECENT
RECENT.html
authors/00whois.html
authors/01mailrc.txt.gz
authors/id/A/AA/AASSAD/CHECKSUMS
...
Но, если Вы хотите получить список
абсолютных ссылок Вы можете использовать метод new_abs, изменив
цикл while следующим образом:
while( $html =~ m/<A HREF=\"(.*?)\"/g ) {
print URI->new_abs( $1, $response->base ) ,"\n";
}
($response->base
модуля HTTP::Message используется для определения базового адреса
для преобразования относительных ссылок в абсолютные.)
Теперь наша программа выдаёт то, что ндо:
http://www.cpan.org/MIRRORING.FROM
http://www.cpan.org/RECENT
http://www.cpan.org/RECENT.html
http://www.cpan.org/authors/00whois.html
http://www.cpan.org/authors/01mailrc.txt.gz
http://www.cpan.org/authors/id/A/AA/AASSAD/CHECKSUMS
...
См. Главу 4, "URLs", книги Perl & LWP для большей информации об объектах URI.
Конечно, использование regexp для
выделения адресов является слишком прмитивным методом, поэтому для более серьёзных
программ следует использовать модули "грамматического разбора HTML"
подобные HTML::LinkExtor или HTML::TokeParser, или,
даже может быть, HTML::TreeBuilder.
Другие свойства броузера
Объекты LWP::UserAgent
имеют множество свойст для управления собственной работой.Вот некоторые из них:
-
$browser->timeout(15): Этот метод устанавливает максимальное количество времени на ожидание ответа сервера. Если по истечении 15 секунд(в данном случае) не будет получено ответа, то броузер прекратит запрос. -
$browser->protocols_allowed( [ 'http', 'gopher'] ): Устанавливаются типы ссылок, с которыми броузер будет "общаться"., в частности HTTP and gopher. Если будет осуществена попытка получить доступ к какому-то документу по другому протоколу (например, "ftp:", "mailto:", "news:"), то не будет даже попытки соединения, а мы получим ошибку 500, с сообщением подобным: "Access to ftp URIs has been disabled". -
use LWP::ConnCache;: После этой установки объект броузера пытается использовать HTTP/1.1 "Keep-Alive", который ускоряет запросы путем использования одного соединения для нескольких запросов к одному и тому же серверу.
$browser->conn_cache(LWP::ConnCache->new()) -
$browser->agent( 'SomeName/1.23 (more info here maybe)' ): Определяем как наш броузер будет идентифицировать себя в строке "User-Agent" HTTP запросов. По умолчанию, он отсылает"libwww-perl/versionnumber", т.е. "libwww-perl/5.65". Вы можете изменить это на более информативное сообщение:$browser->agent( 'SomeName/3.14 (contact@robotplexus.int)' );Или, если необходимо, Вы можете прикинутся реальным броузером:
$browser->agent( 'Mozilla/4.0 (compatible; MSIE 5.12; Mac_PowerPC)' ); -
push @{ $ua->requests_redirectable }, 'POST': Устанавливаем наш броузер на то, чтобы выполнять переадресацию на POST запросы (так делает большинство современных броузеров(IE, NN, Opera)), хотя HTTP RFC говорит нам о том, что это вообще-то не должно осуществляться.
Для большей информации читайте полную документацию по LWP::UserAgent.
Написание учтивых роботов
Если Вы хотите убедится, что Ваша
программа, основанная на LWP, обращает внимание на файлы robots.txt и
не делает слишком много запросов за короткий период времени Вы можете использовать
LWP::RobotUA вместо LWP::UserAgent.
LWP::RobotUA - это
почти LWP::UserAgent, и Вы можете использовать его также:
use LWP::RobotUA;
my $browser = LWP::RobotUA->new(
'YourSuperBot/1.34', 'you@yoursite.com');
# Your bot's name and your email address
my $response = $browser->get($url);
Но HTTP::RobotUA добавляет
следующие возможности:
-
Если robots.txt на сервере, на который ссылается
$url, запрещает Вам доступ к$url, то тогда объект$browser(учтите, что он принадлежит классуLWP::RobotUA) не будет запрашивать его, и мы получим в ответ ($response) ошибку 403, содержащую строку "Forbidden by robots.txt". Итак, если Вы имеете следующую строчку:die "$url -- ", $response->status_line, "\nAborted" unless $response->is_success;тогда программа должна завершится сообщением:
http://whatever.site.int/pith/x.html -- 403 Forbidden by robots.txt Aborted at whateverprogram.pl line 1234 -
Если
$browserувидит, что общался с этим сервером не так давно, то тогда он сдлеает паузу(подобноsleep) для предотвращения осуществления большого количества запросов за короткий срок. Какова будет задержка? В общем-то, по умолчанию, это - 1 минута, но Вы можете контролировать это путём изменения атрибута$browser->delay( minutes ).Например:
$browser->delay( 7/60 );Это означает, что броузер сделает паузу, когда это будет нужно, пока со времени предыдущего запроса не пройдёт 7 секунд.
Для большей информации читайте полную документацию по LWP::RobotUA.
Использование прокси-серверов
В некоторых случаях Вы хотите или Вам необходимо использовать прокси-сервера для доступа к определённым сайтам или для использования определённого протокола. Наиболее часто такая необходимость возникает, когда Ваша LWP-программа запускается на машине, которая находится "за firewallом".
Для того, чтобы броузер использовл
прокси, который определён в переменных окружения(HTTP_PROXY), вызовите
env_proxy перед какими-то запросами. В частности:
use LWP::UserAgent;
my $browser = LWP::UserAgent->new;
#И перед первым запросом:
$browser->env_proxy;
Для большей информации о параметрах
прокси читайте документацию
по LWP::UserAgent, в частности обратите внимание на методы proxy,
env_proxy и no_proxy.
HTTP Authentication(идентификация)
Многие сайты ограничивают доступ к своим страницам используя "HTTP Authentication". Это не просто форма, куда Вы должны ввести свой пароль для доступа к информации, это особый механизм, когда HTTP серверпосылает броузеру сообщение, которое гласит: "That document is part of a protected 'realm', and you can access it only if you re-request it and add some special authorization headers to your request"("Этот документ является частью защищённой 'области' и Вы можете получить доступ к нему, если Вы ещё раз сделаете запрос, добавив некоторые специфичные заголовки к Вашему запросу").
Например, администраторы сайта Unicode.org ограничивают доступ для программ сбора emailов к их архивам электронных рассылок, защищая их при помощи HTTP Authentication, существует общий логин и пароль для доступа(на http://www.unicode.org/mail-arch/)--логин - "unicode-ml" и пароль - "unicode".
Например, рассмотрим этот URL, который является частью защищённой области Веб-сайта:
http://www.unicode.org/mail-arch/unicode-ml/y2002-m08/0067.html
Ели Вы попытаетесь загрузить эту страничку броузером, то получите инструкцию: "Enter username and password for 'Unicode-MailList-Archives' at server 'www.unicode.org'", или в графическом броузере что-то наподобие этого:
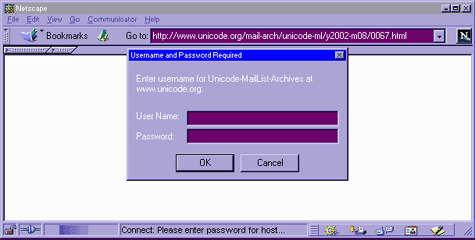
В LWP, если Вы запустите следующее:
use LWP 5.64;
my $browser = LWP::UserAgent->new;
my $url =
'http://www.unicode.org/mail-arch/unicode-ml/y2002-m08/0067.html';
my $response = $browser->get($url);
die "Error: ", $response->header('WWW-Authenticate') ||
'Error accessing',
# ('WWW-Authenticate' is the realm-name)
"\n ", $response->status_line, "\n at $url\n Aborting"
unless $response->is_success;
То тогда получите ошибку:
Error: Basic realm="Unicode-MailList-Archives"
401 Authorization Required
at http://www.unicode.org/mail-arch/unicode-ml/y2002-m08/0067.html
Aborting at auth1.pl line 9. [or wherever]
потому что $browser
не знает логина и пароля для области ("Unicode-MailList-Archives") на хосте("www.unicode.org").
Наипростейший метод дать узнать броузеру логин и пароль - использовать метод
credentials. Синтаксис следующий:
$browser->credentials(
'servername:portnumber',
'realm-name',
'username' => 'password'
);
В большинстве случаев порт номер
80 - является TCP/IP портом по умолчанию для HTTP; и Вы можете использовать
метод credentials до каких-либо запросов. Например:
$browser->credentials(
'reports.mybazouki.com:80',
'web_server_usage_reports',
'plinky' => 'banjo123'
);
Итак, если мы добавим следующее
сразу после строки $browser = LWP::UserAgent->new; :
$browser->credentials( # add this to our $browser 's "key ring"
'www.unicode.org:80',
'Unicode-MailList-Archives',
'unicode-ml' => 'unicode'
);
и запустим, то запрос пройдёт.
Accessing HTTPS URLs
Когда Вы хотите получить доступ к странице через HTTPS, то всё будет работать как и в случае, если бы мы имели дело с обыкновенным HTTP протоколом, если Ваш LWP имеет поддержку HTTPS (через соответствующую Secure Sockets Layer library). Например:
use LWP 5.64;
my $url = 'https://www.paypal.com/'; # Yes, HTTPS!
my $browser = LWP::UserAgent->new;
my $response = $browser->get($url);
die "Error at $url\n ", $response->status_line, "\n Aborting"
unless $response->is_success;
print "Whee, it worked! I got that ",
$response->content_type, " document!\n";
Если Ваш LWP не имеет поддержки HTTPS, тогда ответ будет не удачным и Вы получите следующую ошибку:
Error at https://www.paypal.com/
501 Protocol scheme 'https' is not supported
Aborting at paypal.pl line 7. [or whatever program and line]
Если Ваш LWP имеет поддержку HTTPS,
тогда ответ должен быть удачным, и Вы должны отработать с $response
как и с клюбым обыкновенным HTTP-ответом.
Для получения информации по установке поддержки HTTPS для LWP прочитайте файл README.SSL, который входит в дистрибутив libwww-perl.
Получение больших документов
Когда Вы запрашиваете большой(или
потенциально большой) документ, возникает проблема со стандартными действиями
с методами запросов (подобно $response = $browser->get($url))
с тем, что весь объект ответа должен храниться в памяти. Если ответом является
30-мегабайтный файл, то это, мягко говоря, не очень хорошо для Вашей оперативной
памяти и размером Вашего процесса в ней.
Хорошей альтернативой является сохранение файла на диск, а не в память. Синтаксис следующий:
$response = $ua->get($url,
':content_file' => $filespec,
);
Например,
$response = $ua->get('http://search.cpan.org/',
':content_file' => '/tmp/sco.html'
);
Когда Вы используете опцию:content_file,
объект $response будет иметь все нормальные заголовки, однако $response->content
будет пустым.
Отмечу, что опция ":content_file"
не поддерживалась старыми версиями LWP, поэтому Вы должны принять это во внимание,
добавив use LWP 5.66;для проверки версии LWP, если Вы считаете,
что Ваша программа может быть запущена на системах с более старыми версиями
LWP.
Если Вы хотите, чтобы программа была совместима с более старыми версиями LWP, тогда используйте синтаксис, который позволяет сделать тоже самое:
use HTTP::Request::Common;
$response = $ua->request( GET($url), $filespec );
Ссылки
Помните, что эта статья - это всего лишь самое первое введение в LWP-- для более глубокого изучения LWP и задач, связанных с LWP, Вам стоит прочитать следующие материалы:
-
LWP::Simple: простые функции для скачивание, рабора заговков и зеркалирования адресов. -
LWP: Обзор модулей libwww-perl. -
LWP::UserAgent: Класс для объектов, которые исполняют роль "виртуальных броузеров". -
HTTP::Response: Класс объектов, которые представляют "ответ", такой как в$response = $browser->get(...). -
HTTP::MessageиHTTP::Headers: Классы для предоставление большего количества методов дляHTTP::Response. -
URI: Класс для объектов, которые представляют собой абсолютные или относительные URLы. -
URI::Escape: Функции для работы с escape-последовательностями в адресах (например преобразование туда и обратно из "this & that" в "this%20%26%20that"). -
HTML::Entities: Функции для работы с escape-последовательностями в HTML (например преобразование туда и обратно из "C. & E. Brontë" в "C. & E. Brontë"). -
HTML::TokeParser и HTML::TreeBuilder: Классы для грамматического разбора("парсинга") HTML. -
HTML::LinkExtor: Класс для нахождения ссылок в документах. -
И последнее, но не наименьшее, моя книга Perl & LWP.
Copyright ©2002, Sean M. Burke.
Translation into Russian by Dmitry Nikolayev.
You can redistribute this document and/or modify it, but only under the same
terms as Perl itself.