CodeNet / Веб программирование / Поисковые системы
Методика создания индексных файлов для осуществления полнотекстового поиска в сети Интернет.
Постановка задачи.
В ставших уже классическими работах Д. Кнута, Н. Вирта, У. Ахо и других авторов приводится ряд алгоритмов, позволяющих проводить эффективный поиск в текстовых документах. Наиболее известны из них алгоритмы Бойера-Мура (Boyer-Moore) и Кнута-Морриса-Пратта (Knuth-Morris-Pratt). При сравнительно малых затратах на предварительную обработку текста, эти алгоритмы обеспечивают достаточно высокую скорость поиска. Однако их применение при работе в Сети чрезвычайно осложняется необходимостью просматривать в поисках образца множество текстов, число которых может достигать сотен миллионов. При этом затраты времени возрастают линейно с ростом количества обрабатываемых документов.
В связи с этим, в процессе построения поисковых машин для работы с глобальными массивами данных, значительное внимание уделяется предварительной подготовке (индексированию) текстов. Следует отметить тот факт, что затрачиваемое на построение индексов время во много раз превышает непосредственно требуемое для проведения поиска образца. Кроме того, при подготовке и использовании индексных структур резко возрастают и прочие затраты, в частности объемы памяти для хранения дополнительной поисковой информации.
В данной статье рассматривается разработанная автором методика построения поисковых индексов, применяемая для поддержки полнотекстового поиска в массиве документов, обрабатываемых системой КИС ЖКХ РФ.
Используемая методика.
Прежде всего, сформулируем основные требования к создаваемым индексам. Индексные структуры должны быть легко делимы на независимые части, каждая из которых может обрабатываться отдельно. Их размер должен быть минимален. Представление структур и алгоритмы для работы с ними необходимо оптимизировать на процессах извлечения информации, тогда как объем затрат на изменение информации (обновление индексов) не является существенным.
Исходя из этого, подходы к построению индексов логически разбиваются на две группы: алгоритмы построения индексов и алгоритмы поиска информации на основе данных индексов. На верхнем уровне абстракции алгоритм построения индексов можно представить следующими шагами:
- обработка отдельного документа и подготовка набора структур, его описывающих;
- преобразование полученных структур с одновременным сжатием и оптимизацией с точки зрения доступа к информации;
- добавление преобразованных структур, описывающих отдельный документ, к общим индексам поисковой машины и соответствующее их перестроение.
В рамках данной статьи отсутствует возможность рассмотреть каждый из этих шагов в отдельности, поэтому ограничимся обзором набора структур данных, создаваемых в процессе работы алгоритма. При этом отметим тот факт, что структуры перечисляются в порядке, фактически соответствующем алгоритму поиска образца:
- получение целочисленных идентификаторов запрошенных образцов для поиска;
- получение кодированного множества документов по найденным идентификаторам;
- извлечение набора идентификаторов документов из данного кодированного множества;
- просмотр информации, описывающей найденные документы, выделение и сортировка подмножества документов согласно заданным пользователем ограничениям;
- выдача списка документов по результатам предыдущего шага.
Обзор индексных структур.
Общий словарь. Представляет собою бинарное дерево, ставящее в соответствие строковому представлению образца для поиска (лексемы) его уникальный идентификатор. В реализации применяется B-дерево 2-го порядка, позволяющее сократить расходы на балансировку при обновлении словаря. При этом гарантируется, что время поиска образца будет пропорционально log N, где N - объем (мощность) словаря.
Множество масок документов. Таблица, задающая для каждого идентификатора лексемы битовую маску, кодирующую информацию о множестве документов, в которых эта лексема встречается. Эти маски представляют собой последовательности целых чисел (слов), каждое из которых рассматривается в качестве битового массива. Таким образом, множество документов, содержащих некую лексему хранится в виде характеристической функции, так, что каждый ее ненулевой бит указывает на присутствие соответствующего документа во множестве. Схематично данная связь показана на рисунке 1.
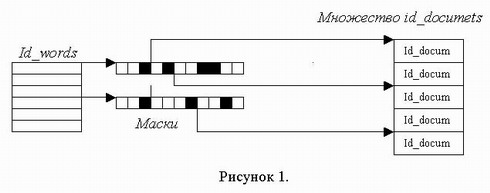
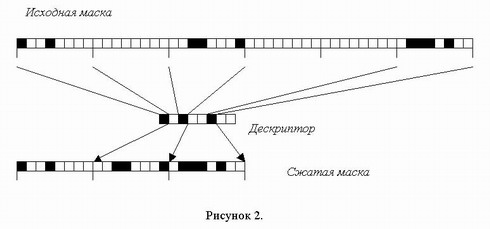
Для ряда лексем с неравномерной функцией распределения хранимые таким образом маски окажутся слишком разреженными, то есть большое количество слов их составляющих будут содержать только нулевые биты. Знание об этом используется для дополнительной экономии памяти. Для этого хранимые маски дополнительно упаковываются по следующему алгоритму: каждое ненулевое слово исходной маски сохраняется и соответствующий ему бит дескриптора выставляется в 1. Каждое нулевое слово удаляется, а соответствующий ему бит выставляется в 0. Данное преобразование проиллюстрировано рисунком 2. Следует отметить тот факт, что эффективность подобного сжатия обратно пропорциональна длине слова.
Структура для извлечения идентификаторов документов. Структура, позволяющая по участку маски документов выделить сам документ. При этом для каждого документа хранится его идентификатор, категория, номер слова, на него указывающего, и маска, выделяющая из заданного слова, соответствующий ему бит.
Структуры, описывающие набор лексем в документе. Для каждого документа хранится следующий набор структур.
Бинарное дерево идентификаторов составляющих его уникальных лексем. Каждый элемент этого дерева содержит индекс массива, содержащего массив позиций занимаемых этой лексемой, одновременно являющийся также индексом массива, содержащего описание лексемы. При конвертации это дерево преобразуется в упорядоченный массив идентификаторов лексем, что обеспечивает некоторый выигрыш памяти при сохранении скорости поиска.
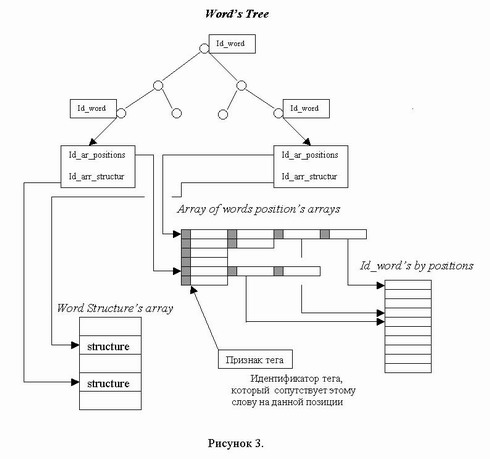
Кроме того, для каждого документа создается массив массивов позиций лексем, причем для каждой позиции в ее старшие биты помещается признак тега, который маркирует лексему на соответствующей позиции. Также формируется массив идентификаторов лексем в порядке расположения в тексте и массив структур, описывающих все уникальные лексемы в отдельности. Перечисленные структуры изображены на рисунке 3.
Описание уникальной лексемы. Для каждой уникальной лексемы в документе хранится набор признаков. Эта информация вычисляется при обработке документа на первом шаге и используется для сортировки массива найденных документов, а также для выборки подмножества документов с уточняющими критериями. Используются следующие признаки: тип лексемы, количество ее вхождений в документ, коэффициент близости к началу (номер позиции ее первого вхождения в документ) и суммарный вес лексемы в документе (сумма весовых коэффициентов по каждому вхождению лексемы в документ).
Тип лексемы. В зависимости от категории, к которой принадлежит документ, лексема может являться обычной либо характеристической. Кроме того, она может иметь особое значение для данного документа. Особость лексемы определяется исходя из ряда соображений, например при оценке мета-описания документа.
Общее описание документа. Кроме информации о наборе лексем для каждого документа хранится также его общее описание, в которое входят: название документа, его автор, дата создания, тип документа и иная информация, определяемая в контексте приложения.
Список соответствия идентификаторов документов их содержимому. Исходные документы хранятся на диске в некотором виде (MS Word, HTML, XML, Plain TEXT, RTF, etc) и могут быть представлены пользователю для просмотра и закачивания на диск согласно списку идентификаторов, полученному на предыдущем шаге.
Применение.
Основным вопросом применения описанной методики на практике является обеспечение разумного баланса между объемом хранимых индексных файлов и скоростью доступа к информации, в них содержащейся. При этом немаловажными оказываются вопросы представления описанных выше структур, их размещения на диске, в базах данных, либо в оперативной памяти компьютера. Используемые структуры данных и алгоритмы с ними работающие должны быть тщательно протестированы и максимально оптимизированы, особенно это касается той части системы, которая обслуживает клиентов в режиме поиска информации. При реализации методики необходимо помнить о многопользовательском доступе к системе в этом режиме, что фактически в N раз увеличивает ресурсоемкость системы (где N - число одновременно обращающихся к системе клиентов). В связи с этим остро встает вопрос кэширования части извлекаемой информации в оперативной памяти, а также своевременной очистки кэшей.
Для иллюстрации сказанного ниже публикуется ряд соображений, использованных автором при построении поискового модуля системы КИС ЖКХ РФ. Приводимая в приложениях информация не претендует на полноту и однозначность, однако дает возможность читателю представить некоторые особенности реализации методики.
Приложение 1.
Описание особенностей первого этапа алгоритма построения индексов.
Задачей данного этапа является обеспечение простого и надежного представления поступившего документа через множество слов его составляющих с тем, чтобы в дальнейшем использовать эту информацию для регистрации документа в поисковой системе. При этом основное внимание должно быть уделено простоте создания и изменения описывающих структур в процессе анализа документа. Объем занимаемой формируемыми структурами памяти на этом этапе не слишком существенен.
Используемые словари. При работе анализатора используются словарь стоп-слов (предлогов, союзов, частиц и прочих лексем, не несущих смысловой нагрузки), словарь весов для используемых XML-тегов и набор словарей характеристических лексем для каждой предметной области. Данные словари предлагается представить в виде хеш-таблиц, что связано с тем, что их размер легко оценить заранее, а также с тем, что они достаточно мало будут изменяться в процессе жизненного цикла анализатора. Словарь стоп-слов создается заранее, словари характеристической области должны накапливаться в процессе работы приложения, а по прошествии некоторого времени, редактироваться администратором, перестраиваться и подключаться к анализатору.
Обработка документа. В процессе разбиения документа на лексемы анализатор формирует из уникальных лексем простое двоичное дерево. Стоп-слова при этом исключаются и их позиции в документе не учитываются. Отметим, что в узлах дерева на этом этапе содержатся сами лексемы ("имена" слов). Вновь создаваемые вершины дерева нумеруются инкрементирующимся счетчиком, его значение используется в качестве первого индекса массива массивов позиций лексем и массива описаний лексем. Кроме того, этот индекс помещается в ячейку массива позиций документа. В связи с тем, что размер этих массивов динамически растет, в программе они должны быть представлены линейными списками.
В связи с небольшой мощностью словаря уникальных лексем для одного документа и необходимостью обеспечить быстрое включение в дерево новых данных, какая либо его балансировка не производится. Согласно Вирту, это увеличивает среднюю длину пути поиска на 39%, что на данном этапе не существенно. Следует обратить внимание на то, что в текущем представлении коэффициент близости фактически оказывается равен индексу в массиве описаний и поэтому отдельно может не сохраняться.
Подготовка построенных структур к включению в общий индекс поисковой системы. Прежде чем индекс нового документа будет добавлен в систему поиска, он должен быть преобразован с целью экономии объема памяти им занимаемого, а также обеспечения высокой скорости доступа к его содержимому. В частности, все списковые структуры должны быть заменены массивами фиксированной длины, структуры, описывающие уникальные лексемы - упакованы в массив длинных целых, а список лексем документа - заменен на список их идентификаторов согласно общему словарю системы.
Приложение 2.
Пример представления одиночного документа набором структур.
Пусть исходным текстом нашего документа является следующая фраза. Простой тест обрабатывающий наш документ. Это наш простой пример и простой документ наш.
Предположим, что вес каждого из обычных лексем документа равен единице. Вес для слова "тест", написанного увеличенным шрифтом, равен двум. Слово "обрабатывающий" является характеристическим и его вес равен пяти. Лексема "документ" выделена жирным, ее вес равен трем, а союз "и" является стоп-словом, и потому не используется при построении структур. Ниже приведен вид структур, построенных при обработке данного примера анализатором.