
Алгоритм Хаффмана
Алгоритм Хаффмана (Отрывок из курсовой работы)
Проще всего рассмотреть алгоритм Хаффмана на простейшем примере представленном на рисунке 1. Предположим, что нам надо заархивировать следующую символьную последовательность: "AAABCCD". Без архивации эта последовательность занимает 7 байт. С архивацией по методу RLE она бы выглядела бы так:
3,"A",1,"B",2,"C",1,"D"
то есть возросла бы до 8-ми байтов. А алгоритм Хаффмана может сократить ее почти до двух байтов, и вот как это происходит. 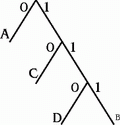
Прежде всего, отметим, что разные символы встречаются в нашем тексте по-разному. Чаще всего присутствует буква "A". Можно составить таблицу частот:
Символ 'A','B','C,'D'
Количество повторений '3','1','2','1'
Затем эта таблица используется для построения так называемого двоичного дерева (рис 1). Именно это дерево используется для генерации нового сжатого кода.
Левые ветви дерева помечены кодом 0,а правые-1. Имея такое дерево, легко найти любого символа, если идти от вершины к нужному символу. Итак в нашем случае алгоритм выглядит так:
Если символ равен "A" то ему присваивается двоичный ноль, в противном случае - единица и рассматривается следующий бит, если символ - "C", то он получит код 10, в противном случае 11. Если символ "D", то его код - 110, в противном случае-111.
Обратите внимание на то, что в алгоритме Хаффмана разные символы будут иметь разную битовую длину, и не надо иметь ни какого разделителя между символами. Например, если вы попробуете декодировать с помощью рисунка 1 последовательность:
0001111111010110
то получите текст:"AAABBCCD"
0 0 0 111 111 10 10 110A A A B B C C D
а, рассмотренным нами выше текст "AAABCCD" займет всего 13 бит (а это меньше двух байтов).
A A A B C C D0 0 0 111 10 10 110
Как видно, результат довольно впечатляющий, но рано радоваться, не все проблемы еще исчерпаны.
Замечание 1.
Первая проблема состоит в том, что на разных файлах метод может генерировать различные двоичные деревья. И действительно, например в русских текстах чаще всего встречается буква "А" и она будет стоять у вершины дерева и ей будет присвоен код равный двоичному нулю. А вот в англоязычных текстах, например самая частая буква - это "E" и этот код будет присвоен ей. А если ваш файл - не текст, а какая-нибудь арифметическая таблица, то там чаще встречается цифра "0", а в файлах графики чаще встречаются коды "0" и "255". Представляете, что будет если программа декомпрессор ничего не будет знать об исходном двоичном дереве. То естественно она ваш файл не разархивирует, так как не знает какие коды сопоставляются последовательностям 0, 10, 110, 1110 и т. д.
Первое решение приходит сразу, в самом начале архивированного файла надо записывать само дерево с помощью которого проходила архивация. Но тут вот где "собака порылась", ведь если мы архивировали файл длиной 8 байтов и получили 2 байта, а теперь к нему приложим таблицу длиной 8- 10 байтов, то ценность нашей архивации будет отрицательной. Таким образом на коротких файлах такой метод Хаффмана ничего не даст и чем длиннее файл, тем лучше будет эффект.
Второе решение может быть например, таким. Мы можем иметь несколько "стандартных" деревьев, первое например, для текста на русском языке, второе для текста на английском языке, третье для графических файлов (BMP, PCX), четвертое для блоков машинного кода и т. д. и т. п. Если эти деревья (таблицы соответствия) достаточно стандартны, то можно таблицу к файлу не прикладывать, а перед сжатым файлом давать один байт, в котором записан номер стандартной таблицы.
В этом случае компрессирующая программа может проверить на вашем файле несколько разных методов, посмотреть, какой будет эффективнее, припишет к выходному файлу префиксный байт и потом осуществит саму архивацию. А декомпрессирующая программа по первому байту определит каким методом была произведена компрессия, и поскольку таблицы стандартны произведет декодирование.
Замечание-2
В описанном мною алгоритме очень большая проблема связана с определением конца файла. Как декомпрессирующая программа поймет, что файл закончен? какой маркер поставить в финале?.
Первый вариант связан опять же с возможностью создания специального хедера, который записывается перед файлом и в котором указано количество бит в файле. Декомпрессирующая программа работает только с этим числом и не одним битом больше.
Второй вариант изящнее, в качестве маркера используется символ, которого не может быть в исходном файле, поэтому любой такой символ будет считаться маркером конца файла. Но к сожалению, очень редко можно заранее знать точно, что таких-то или таких-то символов не может быть в файле. Например, если вы делаете компрессор общего назначения, то он должен работать с чем угодно. В этом случае вводят дополнительный фальшсимвол 256-ой. Он будет самым редко встречающимся в файле, и может быть встречен в нем только один раз, и как самый редко встречающийся символ, он будет самым длинным, и для его записи будет использована довольно длинная битовая последовательность, но по скольку это происходит только один раз, в этом нет ни чего страшного. Хотя старый принцип остается в действии: "На коротких файлах алгоритм теряет эффективность.
Замечание-3.
Рассмотрим дерево на рисунке 1. В соответствии с ним, мы можем составить следующую таблицу соответствия:
A 0B 10C 110..................252 символ 1111…10253 символ 1111…110254 символ 1111…1110255 символ 1111…11110
Не трудно посчитать, что 255 символ занимал бы 256 бит, а это 32 байта, (не слабо да!), а это свело-бы на нет все преимущества компрессии.
С этой проблемой нужно справляться применением какой либо иной системой двоичного кодирования (А их может быть не мало).
В своей работе я рассмотрю два варианта, один простой и один сложный.
Вариант 1 (простой)
Договоримся, что мы как бы разобьем все символы нашего файла на группы по числу битов в номере символа. И будем строить новое представление двоичного числа из двух половинок. Левая половинка указывает на номер группы вашего числа сколько единичек слева, таков и номер группы. Правая половинка указывает на номер числа в группе. Обратимся к конкретным примерам:
Пример 1:Символ No5. В двоичной форме 5=101. Длина - 3 бита Это число из третьей группы, в которую входят числа 4..7
Порядковый номер в группе - 001 (номер 000 у числа 4) В итоге мы имеем следующее новое представлена:
5 = 111 000“номер группы” = “номер в группе”
Пример 2:Символ No10. В двоичной форме 10=1010. Длина четыре бита Это число из четвертой группы, в которую входят числа 8.. 15. Порядковый номер в группе - 0010. В итоге мы имеем следующее представлена:
10=1111 0010
Пример 3:Символ No44. В двоичной форме 44=101100. Это число из шестой группы, в которую входят числа 32.. 64. Порядковый номер в группе - 001100. В итоге мы имеем следующее представлена:
44-111111 001100
На запись ушло 12 битов, это и есть расплата за то, что самый часто встречающийся символ заменили одним битом.
Теперь можно написать алгоритм перекодировки из обычной системы двоичного кодирования в рассмотренную выше.
- Берется двоичное число.
- Первая единица в нем заменяется на "0"
- Слева к числу приписывается столько единиц, сколько битов в исходном числе.
Теперь посмотрим, как работает декомпрессирующая программа. Пусть на нее поступила произвольная последовательность битов,например:
11010101000111001111101010101010
-всего 30 битов
Количество ведущих единиц указывает на длину двоичного кода. Режем текст по ведущим единицам:
1101,0,10,10,0,0,111001,11110101,10,10
А теперь вместо двоичных значений поставим порядковые номера символов:
3,0,1,1,0,0,5,12,1,1
-всего 10 символов
Как можно заметить декодирование происходит вполне однозначно и несложно. Можно оценить эффективность компрессии 10 символов у нас хранилась в 30 битах (примерно в четырех байтах).Неплохо!!!
Во-первых, можно сразу отметить, что для записи 255-го символа нам потребуется вместо обычных восьми битов нам потребуется 16, и остается уповать на то, что такой символ в файле будет редок.
Во-вторых, можно отметить еще одну интересную деталь. Мы теперь можем иметь дело и с 256-ым и с 500-ым символом Коды не ограничены стандартной длиной одного байта и поэтому мы можем иметь в нашем символьном наборе хоть миллион символов. Поскольку один миллион это два в двадцатой степени то для его записи нам потребуется 2*20=40 битов, то есть всего пять байтов. Может это и расточительство, но ведь на этот один "символ" можно подвешивать не один символ. Так например, можно считать, что слово
"RECTANGLE" это 256-ой символ, а слово "REPEAT"- это 257-ой символ. Неплохо, когда архивируешь тексты Паскаля.
Вариант 2 (Рекуррентная система)
Этот вариант совершенствования двоичной системы несколько сложнее предыдущего, но у него есть свои преимущества. Так, на больших символьных наборах (от 512 и выше) этот вариант наиболее эффективен.
0 01 102 11003 11014 11100005 11100016 11100107 1110011
В левой графе - номер символа, в правой графе - его представление в данной системе двоичного кодирования.
Рассмотрим, например как в этой системе образуется двоичное представление числа 5.
Все начинается с обычной двоичной формы 5=101. Далее берется первый бит (1), а последние два бита (10) oоткладываются в остаток r[5]. Измеряется длина этого остатка l (r[5]). Она равна двум битам. Между первой единицей и остатком записывается рекуррентное представление числа 2 - p(2).
p(5)=1+p(l(r[5]))+r[5]=1+p(2)+01p(2)=1+p(l(r[1]+0=1+p(1)+0p(1)=10
Итого: p(5)=1 1 10 0 01 = 1110001
Рассмотрим еще один пример для числа 10:
10 dec = 1010 binp(10)=1+p(l(r[10]))+r[0]=1+p(3)+010p(3)=1+p(l(r[1]))+1=1+p(1)+1p(1)=10
Итого: p(10) = 1 1 10 1 010 = 11101010
Теперь для числа 17.
17 dec = 10001 binp(17) = 1+p(4)+0001p(04) = 1+p(2)+00p(02) = 1+p(1)+0p(01) = 01
Итого: p(17)=111100000001
Подведем первые итоги:
№ символа по мере убывания частоты появления Количество бит на символ Вариант №1
| 0 | 01 | 01 |
| 1 | 02 | 02 |
| 2,3 | 04 | 04 |
| 4-7 | 07 | 06 |
| 8-15 | 08 | 08 |
| 16-31 | 12 | 10 |
| 64-127 | 14 | 14 |
| 128-255 | 15 | 16 |
Как видно на конкретных примерах, при малом наборе символов более эффективен первый из рассмотренных мною вариант. Для наборов 128-512 символов эффективность двух вариантов примерно одинакова. Но для очень больших наборов, в которых тысячи кодируемых элементов, по-видимому нет более эффективных систем чем предложенная мною рекуррентная система.
Оставить комментарий
Комментарии




https://studlearn.com/works/details/algoritm-khaffmana-c-395