
Техника Оптимизации Программ (фрагмент) 1/3
kk@sendmail.ru
TEMPORA MUTANTUR, ET NOS MUTAMUR IN ILLIS (Времена меняются и мы меняемся с ними лат.)
Аннотация
 Хотите заглянуть внутрь черного ящика подсистемы оперативной памяти? Хотите узнать: что чувствует, чем дышит и какими мыслями живет каждая микросхема вашего компьютера? Хотите научиться минимальными усилиями создавать эффективный программный код, исполняющийся вдвое-втрое быстрее обычного? Хотите использовать возможности современного оборудования на полную мощь? Тогда - вы не ошиблись в выборе книги!
Хотите заглянуть внутрь черного ящика подсистемы оперативной памяти? Хотите узнать: что чувствует, чем дышит и какими мыслями живет каждая микросхема вашего компьютера? Хотите научиться минимальными усилиями создавать эффективный программный код, исполняющийся вдвое-втрое быстрее обычного? Хотите использовать возможности современного оборудования на полную мощь? Тогда - вы не ошиблись в выборе книги!
Перед вами лежит уникальное практическое пособие по оптимизации программ под платформу IBM PC и операционные системы семейства Windows (UNIX), скрупулезно описывающее архитектуру, философию и принципы функционирования современных микропроцессоров, чипсетов, оперативной памяти, операционных систем, компиляторов и прочих компонентов ПК.
Это одна из тех редких книг, если вообще не уникальная книга, которая описывает переносимую оптимизацию на системном уровне и при этом ухитряется практически не прибегать к ассемблеру.
Здесь вы найдете и оригинальные приемы программирования, и недокументированные секреты, существование которых Intel и Microsoft хотели бы скрыть, и разъяснение туманных пунктов фирменной документации (включая указания на многочисленные ошибки и неточности!), и перечень типовых ошибок программистов, снижающих производительность системы, и вполне готовые к использованию решения, и:
Основной упор сделан на процессоры AMD Athlon, Intel Pentium-III и Intel Pentium-4 и языки программирования Си/Си ++ (впрочем, описываемые техники не привязаны ни к какому конкретному языку, и знание Си требуется лишь для чтения исходных текстов примеров, приведенных в книге).
Об авторе
Если говорить о себе кратко - "я просто познаю окружающий мир и получаю от этого удовольствие". Компьютерами одержим еще со старших классов средней школы (или еще раньше - уже, увы, не помню).
Основная специализация: разработка оптимизирующих компиляторов и операционных систем реального времени для управления производством.
Из всех языков программирования больше всего люблю ассемблер, но при разработке больших проектов предпочитаю Си (реже Cи ++). Для создания сетевых приложений прибегаю к помощи Perl и Java, ну а макросы для Word и Visual Studio пишу на Бейсике. Эпизодически балуюсь Forth и всякими "редкоземельными" языками наподобие Python. Впрочем, важен не сам язык, а мысли, которые этим языком выражают.
Но все-таки, компьютеры - не единственное и, вероятно, даже не самое главное увлечение в моей жизни. Помимо возни с железом и блужданий в непроходимых джунглях защитного кода, я не расстаюсь с миром звезд и моих телескопов, много читаю, да и пишу тоже (в последнее время как-то больше пишу, чем читаю).
"Техника оптимизации программ" - это уже седьмая по счету моя книга. Предыдущие: "Техника и философия хакерских атак", "Техника сетевых атак", "Образ мышления - дизассемблер IDA", "Укрощение Интернет", "Фундаментальные основы хакерства. Искусство дизассемблирования" и "Предсказание погоды по местным атмосферным признакам" были горячо одобрены читателями и неплохо расходились, несмотря на то, что ориентированы они на очень узкий круг читателей (гораздо более узкий, нежели "Техника оптимизации программ").
Помимо этого моему перу принадлежит свыше двухсот статей, опубликованных в журналах "Программист", "Открытые системы", "Инфо-бизнес", "Компьютерра", "LAN", "eCommerce World", "Mobile", "Byte", "Remont & Service", "Astronomy", "Домашний компьютер", "Интерфейс", "Мир Интернет", "Магия ПК", "Мегабайт", "Полный ПК", "Звездочет" и др.
Хакерские мотивы моего творчества не случайны и объясняются по-детски естественным желанием заглянуть "под капот" компьютера и малость "потыкать" его "ломом" и "молоточком", выражаясь, разумеется, фигурально - а как же иначе понять как эта штука работает? Если людей, одержимых познанием окружающего мира, считать хакерами, то я хакер.
Адреса электронной почты для связи с автором: kpnc@programme.ru, kpnc@itech.ru.
Введение в книгу
О серии книг "Оптимизация"
Ну вот, - воскликнет, иной читатель, - опять серия! Да сколько же можно этому Касперски объявлять серий?! И что интересно: все серии разные! Выпущен первый том "Техники сетевых атак", но вот уже года три как нет второго. Объявлен трехтомник "Образ мышления -дизассемблер IDA", но до сих пор вышли только первый и третий тома книги, а второго по-прежнему нет и в обозримом будущем даже и не предвидится. Наконец, "Фундаментальные основы хакерства. Искусство дизассемблирования" - это вновь всего лишь первый том! Так не лучше ли автору сконцентрироваться на чем-нибудь одном, а не метаться по всей предметной области?
Кто-то даже сравнил меня с Кнутом - мол обещал семь томов, а выпустил только три. Но если Кнут выпустил три тома одной книги, то Касперски - по одному тому трех разных. Ситуация осложняется тем, что мой издатель по маркетинговым соображением наотрез отказался называть настоящую книгу томом. Хорошо, пусть это будет не "том", пусть это будет "первая книга серии". (Суть дела от этого все равно не меняется).
Предвидя встречный вопрос читателя о причинах неполноты охвата информации (действительно, настоящая книга ограничивается исключительно одной оперативной памятью и ни слова не обмолвливается о таких важных аспектах оптимизации как, например, планирование потока команд или векторизация вычислений), считаю своим долгом заявить, что в одной-единственной книге просто невозможно изложить все аспекты техники оптимизации и уж лучше остановиться подробно на освещении узкого круга вопросов, чем поверхностно рассказать обо всем.
К тому же, с выпуском данной книги, работа над "Оптимизацией" не прекращается и на будущее запланировано как минимум пять книг этой серии. Ниже все они перечислены в предполагаемом хронологическом порядке.
Первая книга - представленная вашему вниманию - посвящена оперативной памяти, оптимизации на уровне структур данных и алгоритмов их обработки. Ориентирована на прикладных и системных программистов. Настоящая книга включает лишь половину запланированного материала. Остающаяся часть либо выйдет отдельной книгой, либо (что более вероятно) появится во втором издании настоящей книги. Предполагаемый срок выхода: начало 2003 года.
Вторая книга посвящена процессору. В ней будет рассмотрена оптимизация на уровне планирования потоков машинных команд. Книга ориентирована на системных программистов и прикладных программистов, владеющих ассемблером. Предполагаемый срок выхода: начало 2004 года.
Третья книга посвящена автоматической кодогенерации. В ней предполагается рассмотреть устройство оптимизирующих компиляторов, алгоритмы оптимизации, сравнение качества кодогенерации различных компиляторов, как "помочь" оптимизатору. Книга ориентирована на прикладных и системных программистов. Предполагаемый срок выхода: начало 2005 года.
Четвертая книга посвящена вопросам, связанным с подсистемой ввода/вывода. В ней будет рассмотрена оптимизация работы с периферией, описано взаимодействие с такими устройствами как жесткие и лазерные диски, устройства коммуникации, параллельные и последовательные порты, видеоподсистема. Книга ориентирована на прикладных и системных программистов. Предполагаемый срок выхода: начало 2006 года.
Пятая книга посвящена параллельным вычислениям и суперкомпьютерам. Ориентирована на прикладных программистов. Вся информация уникальна, а многая даже засекречена. Поэтому книга будет читаться как самый настоящий детектив про разведчиков. Предполагаемый срок выхода: на настоящий момент пока не известен.
Краткая история создания данной книги
Настоящая книга задумывалась отнюдь не ради коммерческого успеха (который вообще сомнителен - ну много ли людей сегодня занимаются оптимизацией?), а писалась исключительно ради собственного удовольствия (как говорится: UTILE DULCI MISCERE (лат.) - соединять приятное с полезным).
История ее создания вкратце такова: после сдачи моих первых шести книг, обеспечивших мне более или менее сносное существование, у меня появилась возможность неторопливо, без лишней спешки заняться теми исследованиями, которые меня уже давно волновали.
Вплотную столкнувшись с необходимостью оптимизации еще во времена древних и ныне скоропостижно почивших 8-рязрядных машин, я скорее по привычке, чем по насущной необходимости, сохранил преданность эффективному коду до настоящих дней. А потому, не без оснований считал, что "собаку съел" на оптимизации и искренне надеялся, что писать на эту тему мне будет очень легко. Вот только бы выяснить несколько "темных" мест и объяснить некоторые странности поведения процессора, до анализа которых раньше просто не доходили руки...
Но уже к концу первого месяца своих изысканий я понял, что если и "съел собаку", то конечно "древнюю как мамонт", ибо за последние несколько лет техника оптимизации кардинально поменялась, а сами процессоры так усложнились, что особенности их поведения, судя по всему, перестали понимать и сами отцы-разработчики. В общем, вместо трех изначально запланированных на книгу месяцев, работа над ней растянулась более чем на год, причем за это время не было выполнено и десятой части запланированного проекта.
Поверьте! Я вовсе не мячик гонял, а каждый день проводил за компьютером как минимум по 12-15 часов, благодаря чему большая часть прежде темных мест "вышла" из мрака на свет божий и теперь ярко освещена! Быть может, это и не очень производительный труд (и вообще крайне низкий выход в пересчете на символ в час), тем не менее, проделанной рабой в целом я остался доволен. И не удивительно! Изучать "железки" - это до жути интересно. Перед вами - черный ящик, и все, что вы можете так это планировать и осуществлять различные эксперименты, пытаясь описать их результаты некоторой математической моделью, проверяя и уточняя ее последующими экспериментами. И вот так из черного ящика постепенно начинают проступать его внутренности, и вы уже буквально "чувствуете" как он работает и "дышит"! А какое вселенское удовлетворение наступает, когда бессмысленная и совершенно нелогичная паутина результатов всевозможных замеров наконец-то ложится в стройную картину! Чувство, охватывающее вас при этом, можно сравнить разве что с оргазмом!
Соглашения об условных обозначениях и наименованиях
Расшифровку всех непонятных терминов, если таковые встретятся вам по ходу чтения книги, можно узнать в глоссарии. Но, поскольку, в глоссарий по обыкновению все равно практически никто не заглядывает, ниже перечислены обозначения, которые с наибольшей степенью вероятности могут вызвать затруднение.
- Под P6-процессорами понимаются все процессоры с ядром P6, построенные по архитектуре Pentium Pro. К ним принадлежат: сам Pentium Pro, Pentium-II и Pentium-III, а так же процессоры семейства Celeron.
- Процессоры серии Pentium здесь сокращаются до первой буквы "P" и стоящей за ней суффиксом, уточняющим какая именно модель имеется в виду. Например, "P Pro" обозначает "Pentium Pro", а "P-4" - "Pentium-4". Кстати, обратите особое внимание, что индексы "II" и "III" записываются римскими цифрами, а "4" - арабскими. Так хочет фирма Intel (она уже однажды сделала мне замечание по этому поводу), поэтому не будем ей противоречить. В конце концов, хозяин - барин.
- Под "MS VC" или даже просто "VC" подразумевается Microsoft Visual C++ 6.0, а под "BC" - Borland C++ 5.5. Соответственно, "WPP" обозначает "WATCOM C++ 10.0".
- Кабалистическое выражение наподобие "P-III 733/133/100/I815EP" расшифровывается так: "процессор Intel Pentium-III с тактовой частой 773 МГц, частой системной шины 133 МГц и частой памяти 100 МГц, установленный в материнскую плату, базирующуюся на чипсете Intel 815 EP". Соответственно, по аналогии, "AMD Athlon 1050/100/100/VIA KT 133" обозначает: "процессор AMD Athlon с тактовой частотой 1050 МГц, частотой системной шины 100 МГц и частотой работы памяти 100 МГц, уставленный в материнскую плату, базирующуюся на чипсете VIA KT 133".
- Да, чуть не забыл сказать. "Сверхоперативная память" - это русский эквивалент американского термина "cache memory". Здесь он будет использоваться вовсе не из-за самостийной гордости, а просто для того, чтобы избежать излишней тавтологии (частого повторения одних и тех же слов).
Введение в оптимизацию
Pro et contra1 целесообразности оптимизации
Это в наше-то время говорить об оптимизации программ? Бросьте! Не лучше ли сосредоточиться на изучении классов MFC или технологии .NET? Современные компьютеры так мощны, что даже Windows XP оказывается бессильна затормозить их!
Нынешние программисты к оптимизации относятся более чем скептически. Позволю себе привести несколько типичных высказываний:
- "...я применяю относительно медленный и жадный до памяти язык Perl, поскольку на нем я фантастически продуктивен. В наше время быстрых процессоров и огромной памяти эффективность - другой зверь. Большую часть времени я ограничен вводом/выводом и не могу читать данные с диска или из сети так быстро, чтобы нагрузить процессор. Раньше, когда контекст был другим, я писал очень быстрые и маленькие программы на C. Это было важно. Теперь же важнее быстро писать, поскольку оптимизация может привести к столь малому росту быстродействия, что он просто не заметен", - говорит Robert White;
- "...а стоит ли тратить усилия на оптимизацию и чего этим можно достичь? Дело в том, что чем сильнее вы будете адаптировать вашу программу к заданной архитектуре, тем, с одной стороны, вы достигнете лучших результатов, а, с другой стороны, ваша программа не будет хорошо работать на других платформах. Более того, "глубокая" оптимизация может потребовать значительных усилий. Все это требует от пользователя точного понимания чего он хочет добиться и какой ценой", - пишет в своей книге "Оптимизация программ под архитектуру CONVEX C" М. П. Крутиков;
- "Честно говоря, я сам большой любитель "вылизывания" кода с целью минимизации используемой памяти и повышения быстродействия программ. Наверное, это рудименты времен работы на ЭВМ с оперативной памятью в 32 Кбайт. С тем большей уверенностью я отношу "эффективность" лишь на четвертое место в критериях качества программ", - признается Алексей Малинин - автор цикла статей по программированию на Visual Basic в журнале "Компьютер Пресс".
С приведенными выше тезисами, действительно, невозможно не согласиться. Тем не менее, не стоит бросаться и в другую крайность. Начертавший на своем знамени лозунг "на эффективность - плевать" добьется только того, что плевать (причем дружно) станут не в эффективность, а в него самого. Не стоит переоценивать аппаратные мощности! И сегодня существуют задачи, которым не хватает производительности даже самых современных процессоров. Взять хотя бы моделирование различных физических процессов реального мира, обработку видео-, аудио- и графических изображений, распознавание текста: Да что угодно, вплоть до элементарного сжатия данных архиватором a la Super Win Zip!
Да, мощности процессоров растут, но ведь параллельно с этим растут и требования к ним. Если раньше считалось нормальным, поставив программу на выполнение, уйти пить пиво, то сегодняшний пользователь хочет, чтобы все операции выполнялись мгновенно, ну если и не мгновенно, то с задержкой, не превышающей нескольких минут. Не стоят на месте и объемы обрабатываемых данных. Признайтесь, доводилось ли вам находить на своем диске файл размером в сотню-другую мегабайт? А ведь буквально вчера емкость целого жесткого диска была на порядок меньше!
Цель - определяет средства. Вот из этого, на протяжении всей книги, мы и будем исходить. Ко всем оптимизирующим алгоритмам будут предъявляется следующие жесткие требования:
- оптимизация должна быть максимально машинно-независимой и переносимой на другие платформы (операционные системы) без дополнительных затрат и существенных потерь эффективности. То есть никаких ассемблерных вставок! Мы должны оставаться исключительно в рамках целевого языка, причем, желательно использовать только стандартные средства, и любой ценой избегать специфичных расширений, имеющихся только в одной конкретной версии компилятора;
- оптимизация не должна увеличивать трудоемкость разработки (в т. ч. и тестирования) приложения более чем на 10%-15%, а в идеале, все критические алгоритмы желательно реализовать в виде отдельной библиотеки, использование которой не увеличивает трудоемкости разработки вообще;
- оптимизирующий алгоритм должен давать выигрыш не менее чем на 20%-25% в скорости выполнения. Приемы оптимизации, дающие выигрыш менее 20% в настоящей книге не рассматриваются вообще, т. к. в данном случае "овчинка выделки не стоит". Напротив, основной интерес представляют алгоритмы, увеличивающие производительность от двух до десяти (а то и более!) раз и при этом не требующие от программиста сколь ни будь значительных усилий. И такие алгоритмы, пускай это покажется удивительным, в природе все-таки есть!
- оптимизация должна допускать безболезненное внесение изменений. Достаточно многие техники оптимизации "умерщвляют" программу, поскольку даже незначительная модификация оптимизированного кода "срубает" всю оптимизацию на корню. И пускай все переменные аккуратно распределены по регистрам, пускай тщательно распараллелен микрокод и задействованы все функциональные устройства процессора, пускай скорость работы программы не увеличить и на такт, а ее размер не сократить и на байт! Все это не в силах компенсировать утрату гибкости и жизнеспособности программы. Поэтому, мы будем говорить о тех, и только тех приемах оптимизации, которые безболезненно переносят даже кардинальную перестройку структуры программы. Во всяком случае, грамотную перестройку. (Понятное дело, что "кривые" руки угробят что угодно - против лома нет приема).
Согласитесь, что такая постановка вопроса очень многое меняет. Теперь никто не сможет заявить, что, дескать, лучше прикупить более мощный процессор, чем тратить усилия на оптимизацию. Ключевой момент предлагаемой концепции состоит в том, что никаких усилий на оптимизацию тратить как раз не надо. Ну: почти не надо, - как минимум вам придется прочесть эту книжку, а это какие ни какие, а все-таки усилия. Другой вопрос, что данная книга предлагает более или менее универсальные и вполне законченные решения, не требующие индивидуальной подгонки под каждую решаемую задачу.
Это одна из тех редких книг, если вообще не уникальная книга, которая описывает переносимую оптимизацию на системном уровне и при этом ухитряется не прибегать к ассемблеру. Все остальные книги подобного рода, требуют свободного владения ассемблером от читателя. Впрочем, совсем уж без ассемблера обойтись не удалось, особенно в частях, посвященных технике профилировки и алгоритмам машинной оптимизации. Тем не менее, весь код подробно комментирован и его без труда поймет даже прикладной программист, доселе даже не державший отладчика в руках. Ассемблер, кстати, - это довольно "простая штука", но его легче показать, чем описать.
И в заключении позвольте привести еще одну цитату:
"Я программирую, чтобы решать проблемы, и обнаружил, что определенные мысли блокируют все остальные мысли и творческие цели, которые у меня есть. Это мысли об эффективности в то время, когда я пытаюсь решить проблему. Мне кажется, что гораздо логичнее концентрироваться полностью на проблеме, решить ее, а затем творчески запрограммировать, затем, если решение медленное (что затрудняет работу с ним), то..." Gary Mason.
О чем и для кого предназначена эта книга
Настоящая книга описывает устройство и механизмы взаимодействия различных компонентов компьютера и рассказывает об эффективных приемах программирования и технике оптимизации программ, как на уровне машинного кода, так и на уровне структур данных.
Она ориентирована на прикладных программистов, владеющих (хотя бы в минимальном объеме) языком Си, а так же на системных программистов, знающих ассемблер. Описываемые техники не привязаны ни к какому конкретному языку, и знание Си требуется лишь для чтения исходных текстов примеров, приведенных в книге.
В не меньшей степени "Техника оптимизации" будет интересна и лицам, занимающимся сборкой и настройкой компьютеров, поскольку подробно описывает устройство "железа" и разбирает "узкие места" распространенных моделей комплектующих.
В основу данной книги положена уникальная информация и методики, разработанные лично автором. Информация, почерпнутая из технической документации производителей комплектующих, операционных систем и компиляторов, тщательно проверена, в результате чего обнаружено большое количество ошибок, на которые и обращается внимание читателя (тем не менее, автор не гарантирует отсутствие вторичных и "привнесенных" ошибок в самой книге).
Материал книги в основном ориентирован на микропроцессоры AMD Athlon и Intel Pentium-II, Pentium-III и Pentium-4, но местами описываются и более ранние процессоры.
Семь китов оптимизации или
Жизненный цикл оптимизации
Часто программист (даже высококвалифицированный!), обнаружив профилировщиком "узкие" места в программе, автоматически принимает решение о переносе соответствующих функций на ассемблер. А напрасно! Как мы еще убедимся (см. Часть III. "Смертельная схватка: ассемблер VS-компилятор"), разница в производительности между ручной и машинной оптимизацией в подавляющем большинстве случаев крайне мала. Очень может статься так, что улучшать уже будет нечего, - за исключением мелких, "косметических" огрехов, результат работы компилятора идеален и никакие старания не увеличат производительность, более чем на 3%-5%. Печально, если это обстоятельство выясняется лишь после переноса одной или нескольких таких функций на ассемблер. Потрачено время, затрачены силы: и все это впустую. Обидно, да?
Прежде, чем приступать к ручной оптимизации не мешало бы выяснить: насколько не оптимален код, сгенерированный компилятором, и оценить имеющийся резерв производительности. Но не стоит бросаться в другую крайность и полагать, что компилятор всегда генерирует оптимальный или близкий к тому код. Отнюдь! Все зависит от того, насколько хорошо вычислительный алгоритм ложиться в контекст языка высокого уровня. Некоторые задачи решаются одной машинной инструкцией, но целой группой команд на языках Си и Паскаль. Наивно надеяться, что компилятор поймет физический смысл компилируемой программы и догадается заменить эту группу инструкций одной машинной командой. Нет! Он будет тупо транслировать каждую инструкцию в одну или (чаще всего) несколько машинных команд, со всеми вытекающими отсюда последствиями:
Назовем ряд правил оптимизации.
Правило I
Прежде, чем оптимизировать код, обязательно следует иметь надежно работающий не оптимизированный вариант или "...put all your eggs in one basket, after making sure that you've built a really *good* basket" ("...прежде, чем класть все яйца в одну корзину - убедись, что ты построил действительно хорошую корзину").аким образом прежде, чем приступать к оптимизации программы, убедись, что программа вообще-то работает.
Создание оптимизированного кода "на ходу", по мере написания программы, невозможно! Такова уж специфика планирования команд - внесение даже малейших изменений в алгоритм практически всегда оборачивается кардинальными переделками кода. Потому, приступайте к оптимизации только после тренировки на "кошках", - языке высокого уровня. Это поможет пояснить все неясности и "темные" места алгоритма. К тому же, при появлении ошибок в программе подозрение всегда падает именно на оптимизированные участки кода (оптимизированный код за редкими исключениями крайне ненагляден и чрезвычайно трудно читаем, потому его отладка - дело непростое), - вот тут-то и спасает "отлаженная кошка". Если после замены оптимизированного кода на не оптимизированный ошибки исчезнут, значит, и в самом деле виноват оптимизированный код. Ну, а если нет, то ищите их где-нибудь в другом месте.
Правило II
Помните, что основой прирост оптимизации дает не учет особенностей системы, а алгоритмическая оптимизация. Никакая, даже самая "ручная" оптимизация не позволит существенно увеличить эффективность пузырьковой сортировки или процедуры линейного поиска. Правильное планирование команд и прочие программистские трюки ускорят программу в лучшем случае в несколько раз. Переход к быстрой сортировке (quick sort) и двоичному поиску сократят время обработки данных как минимум на порядок, - как бы криво ни был написан программный код. Поэтому, если ваша программа выполняется слишком медленно, лучше поищите более эффективные математические алгоритмы, а не выжимайте из изначально плохого алгоритма скорость по капле.
Правило III
Не путайте оптимизацию кода и ассемблерную реализацию. Обнаружив профилировщиком узкие места в программе, не торопитесь переписывать их на ассемблер. Сначала убедитесь, что все возможное для увеличения быстродействия кода в рамках языка высокого уровня уже сделано. В частности, следует избавиться от прожорливых арифметических операций (особенно обращая внимание на целочисленное деление и взятие остатка), свести к минимуму ветвления, развернуть циклы с малым количеством итераций: в крайнем случае, попробуйте сменить компилятор (как было показано выше - качество компиляторов очень разнится друг от друга). Если же и после этого вы останетесь недовольны результатом тогда...
Правило IV
Прежде, чем порываться переписывать программу на ассемблер, изучите ассемблерный листинг компилятора на предмет оценки его совершенства. Возможно, в неудовлетворительной производительности кода виноват не компилятор, а непосредственно сам процессор или подсистема памяти, например. Особенно это касается наукоемких приложений, жадных до математических расчетов и графических пакетов, нуждающихся в больших объемах памяти. Наивно думать, что перенос программы на ассемблер увеличит пропускную способность памяти или, скажем, заставит процессор вычислять синус угла быстрее. Получив ассемблерный листинг откомпилированной программы (для Microsoft Visual C++, например, это осуществляется посредством ключа /FA), бегло просмотрите его глазами на предмет поиска явных ляпов и откровенно глупых конструкций наподобие: MOV EAX, [EBX]\MOV [EBX], EAX. Обычно гораздо проще не писать ассемблерную реализацию с чистого листа, а вычищать уже сгенерированный компилятором код. Это требует гораздо меньше времени, а результат дает ничуть не худший.
Правило V
Если уж взялись писать на ассемблере, пишите максимально "красиво" и без излишнего трюкачества. Да, недокументированные возможности, нетрадиционные стили программирования, "черная магия", - все это безумно интересно и увлекательно, но: плохо переносимо, непонятно окружающим (в том числе и себе самому после возращения к исходному коду десятилетней давности) и вообще несет в себе массу проблем. Автор этих строк неоднократно обжигался на своих же собственных трюках, причем самое обидное, что трюки эти были вызваны отнюдь не "производственной необходимостью", а: ну, скажем так, "любовью к искусству". За любовь же, как известно, всегда приходится платить. Не повторяйте чужих ошибок! Не брезгуйте комментариями и непременно помещайте все ассемблерные функции в отдельный модуль. Никаких ассемблерных вставок - они практически непереносимы и создают очень много проблем при портировании приложений на другие платформы или даже при переходе на другой компилятор. Единственная предметная область, не только оправдывающая, но, прямо скажем, провоцирующая ассемблерные извращения, это - защита программ, но это уже тема совсем другого разговора...
Если ассемблерный листинг, выданный компилятором, идеален, но программа без видимых причин все равно исполняется медленно, не отчаивайтесь, а загрузите ее в дизассемблер. Как уже отмечалось выше, оптимизаторы крайне неаккуратно подходят к выравниванию переходов и кладут их куда "глюк" на душу положит. Наибольшая производительность достигается при выравнивании переходов по адресам, кратным шестнадцати, и будет уж совсем хорошо, если все тело цикла целиком поместится в одну кэш-линейку (т. е. 32 байта). Впрочем, мы отвлеклись. Техника оптимизации машинного кода - тема совершенно другого разговора. Обратитесь к документации, распространяемой производителями процессоров - Intel и AMD.
Правило VI
Если существующие команды процессора позволяют реализовать ваш алгоритм проще и эффективнее, - вот тогда действительно, "тяпнув" для храбрости пивка, забросьте компилятор на полку и приступайте к ассемблерной реализации с чистого листа. Однако с такой ситуацией приходится встречаться крайне редко, и к тому же не стоит забывать, что вы - не на одиноком острове. Вокруг вас - огромное количество высокопроизводительных, тщательно отлаженных и великолепно оптимизированных библиотек. Так зачем же изобретать велосипед, если можно купить готовый?
Правило VII
Распространенные заблуждения
Оптимизация овеяна многочисленными заблуждениями, которые вызывают снисходительную улыбку у профессионалов, но зачастую необратимо уродуют психику и калечат мировоззрение новичков. Я думаю, профессионалы не обидятся на меня за то, что я потратил несколько страниц книги, чтобы их развеять (естественно, имею в виду заблуждения, а не самих профессионалов).
Заблуждение I
За меня все оптимизирует мой компилятор!
Вера в могущество компиляторов в своем коре абсолютно безосновательна. Хороший оптимизирующий компилятор по большому счету может похвастаться лишь своим умением эффективно транслировать грамотно спроектированный код, т. е. если он не сильно ухудшает исходную программу, то уже только за это его разработчикам следует сказать "спасибо".
Изначально "кривой" код не исправит никакой компилятор, и оптимизирующий - в том числе. Не сваливайте все заботы по эффективности на транслятор! Лучше постарайтесь в меру своих сил и возможностей ему помогать. Как именно помогать, - это тема отдельного большого разговора, которому планируется посвятить третью книгу настоящей серии. Краткий же перечень возможностей машинной оптимизации содержится в третей части данной книги.
Заблуждение II
Максимальная эффективность достижима лишь при программировании на чистом ассемблере, но отнюдь не языке высокого уровня
Перенос программы на ассемблер только в исключительных случаях увеличивает ее эффективность. При трансляции качественного исходного кода, оптимизирующие компиляторы отстают от идеальной ручной оптимизации не более чем на 10%-20%. Конечно, это весьма ощутимая величина, но все же не настолько, чтобы оправдать трудоемкость программирования на чистом ассемблере!
Подробнее о сравнении качества машинной и ручной оптимизации см. Часть III. "Смертельная схватка: ассемблер VS-компилятор".
Заблуждение III
Человек, в отличии от оптимизирующего компилятора, просто физически не способен учесть все архитектурные особенности процессора
Вообще говоря, кроме компиляторов, разрабатываемых Intel, никакие другие компиляторы не умеют генерировать оптимально спланированный с точки зрения микроархитектуры процессора код. Несколькими страницами далее (см. "Практический сеанс профилировки с VTune") вы собственноручно сможете убедиться в этом, а пока же просто поверьте автору на слово.
Замечание рецензента
Под оптимальностью обычно понимается глобальный экстремум некоторой оценочной функции. При оптимизации по скорости ищут абсолютный минимум числа тактов. Очевидно, этот минимум зависит от входных данных. В лучшем случае компилятору можно передать данные тестового прогона (так называемый profiler feedback). На основании этих данных компилятор может более аккуратно присвоить частоты выполнения разным последовательностям инструкций, не более того. Компиляторы Intel ни коим образом не генерируют оптимального кода. Исходя из определения, оптимальная по скорости программа не может быть переписана с сохранением смысла так, что начнет исполняться быстрее. Мне приходилось переписывать вручную порожденный этим компилятором код так, что он становился быстрее.
На мой взгляд, было бы правильнее сказать, что компилятор Intel является единственным из рассматриваемых автором оптимизирующих компиляторов, который способен воспринимать обратную связь от тестовых прогонов и выполнять глобальное распределение регистров. В силу того, что разработчики имеют прямой доступ к документации процессоров Intel, у них больше возможностей принимать во внимание особенности процессоров. Об оптимальности кода или каком-либо принципиальном превосходстве над другими компиляторами говорить не стоит.
Тем не менее, современные процессоры с одной стороны достаточно умны и самостоятельно оптимизируют переданный им на выполнение код. С другой стороны оптимального кода для всех процессоров, все равно не существует и архитектурные особенности процессоров P-II, P-4, AMD K6 и Athlon отличаются друг от друга столь разительно, что все позывы к ручной оптимизации гибнут прямо на корю.
Исключение составляет небольшой круг весьма специфичных задач (например, парольных переборщиков), требования которых к производительности более чем критичны. В этом случае ручная оптимизация действительно "рвет" компилятор, как Тузик грелку.
Заблуждение IV
Процессоры семейства x86 - полный "отстой", вот на PowerPC, например, действительно есть место, где развернуться!
Как гласит народная мудрость "Хорошо там, - где нас нет". Сам я, правда, ничего не оптимизирую под PowerPC, но хорошо знаком с людьми, разрабатывающими под него оптимизирующие компиляторы. И могу сказать, что они далеко не в восторге от его "закидонов", коих у него, поверьте уж, предостаточно.
Да, семейству процессоров x86 присущи многие проблемы и ограничения. Но это ничуть не оправдывает программистов, пишущих "уродливый" код, и палец о палец не ударяющих, чтобы хоть как-то его улучшить.
А "язык" x86 процессоров, между прочим, очень интересен. На сегодняшний день они имеют едва ли не самую сложную систему команд, дающую системным программистам безграничные возможности для самовыражения. Прикладные программисты даже не догадываются сколько красок мира у них украли компиляторы!
Часть 1
Профилировка программ
Профилировкой здесь и на протяжении всей книги мы будем называть измерение производительности как всей программы в целом, так и отдельных ее фрагментов, с целью нахождения "горячих" точек (Hot Spots), - тех участков программы, на выполнение которых расходуется наибольшее количество времени.
Согласно правилу "10/90", десять процентов кода "съедают" девяносто процентов производительности системы (равно как и десять процентов людей выпивают девяносто процентов всего пива). Если время, потраченное на выполнение каждой машинной инструкции, изобразить графически в порядке возрастания их линейных адресов, на полученной диаграмме мы обнаружим несколько высоченных пиков, горделиво возвышающихся над практически пустой равниной, усеянной множеством низеньких холмиков (пример показан далее на рисунке разд. " Практический сеанс профилировки с VTune в десяти шагах") Вот эти самые пики - "горячие" точки и есть.
Почему "температура" различных участков программы столь неодинакова? Причина в том, что подавляющее большинство вычислительных алгоритмов так или иначе сводятся к циклам, - т. е. многократным повторениям одного фрагмента кода, причем зачастую циклы обрабатываются не последовательно, а образуют более или менее глубокие иерархии, организованные по типу "матрешки". В результате, львиную долю всего времени выполнения, программа проводит в циклах с наибольшим уровнем вложения, и именно их оптимизация дает наилучший прирост производительности!
Громоздкие и тормозные, но редко вызываемые функции оптимизировать нет ни какой нужды, - это практически не увеличит быстродействия приложения (ну разве что только в том случае, если они совсем уж будут "криво" написаны).
Когда же алгоритм программы прост, а ее исходный текст свободно умещается в сотню-другую строк, то "горячие" точки нетрудно обнаружить и визуальным просмотром листинга. Но с увеличением объема кода это становится все сложнее и сложнее. В программе, состоящей из тысяч сложно взаимодействующих друг с другом функций (часть из которых это функции внешних библиотек и API - Application Programming Interface, интерфейс прикладного программирования - операционной системы) далеко не так очевидно: какая же именно из них в наибольшей степени ответственна за низкую производительность приложения. Естественный выход - прибегнуть к помощи специализированных программных средств.
Профилировщик (так же называемый "профайлером") - основной инструмент оптимизатора программ. Оптимизация "в слепую" редко дает хороший результат. Помните пословицу "самый медленный верблюд определяет скорость каравана"? Программный код ведет себя полностью аналогичным образом, и производительность приложения определяется самым узким его участком. Бывает, что виновницей оказывается одна-единственная машинная инструкция (например, инструкция деления, многократно выполняющаяся в глубоко вложенном цикле). Программист, затратив воистину титанические усилия на улучшение остального кода, окажется премного удивлен, что производительность приложения едва ли возросла процентов на десять-пятнадцать.
Правило номер один: ликвидация не самых "горячих" точек программы, практически не увеличивает ее быстродействия. Действительно, сколько не подгоняй второго сзади верблюда - от этого караван быстрее идти не будет (случай, когда предпоследней верблюд тормозит последнего - это уже тема другого разговора, требующего глубоких знаний техники профилировки, а потому и не рассматриваемая в настоящей книге).
Цели и задачи профилировки
Основная цель профилировки - исследовать характер поведения приложения во всех его точках. Под "точкой" в зависимости от степени детализации может подразумеваться как отдельная машинная команда, так целая конструкция языка высокого уровня (например: функция, цикл или одна-единственная строка исходного текста).
Большинство современных профилировщиков поддерживают следующий набор базовых операций:
- определение общего времени исполнения каждой точки программы (total [spots] timing);
- определение удельного времени исполнения каждой точки программы ([spots] timing);
- определение причины и/или источника конфликтов и пенальти (penalty information);
- определение количества вызовов той или иной точки программы ([spots] count);
- определение степени покрытия программы ([spots] covering).
Общее время исполнения
Сведения о времени, которое приложение тратит на выполнение каждой точки программы, позволяют выявить его наиболее "горячие" участки. Правда, здесь необходимо сделать одно уточнение. Непосредственный замер покажет, что, по крайней мере, 99,99% всего времени выполнения профилируемая программа проводит внутри функции main, но ведь очевидно, что "горячей" является отнюдь не сама main, а вызываемые ею функции! Чтобы не вызывать у программистов недоумения, профилировщики обычно вычитают время, потраченное на выполнение дочерних функций, из общего времени выполнения каждой функции программы.
Рассмотрим, например, результат профилировки некоторого приложения профилировщиком profile.exe, входящего в комплект поставки компилятора Microsoft Visual C++.
Листинг 1.1. Пример профилировки приложения профилировщиком profile.exe
Func Func+Child Hit
Time % Time % Count Function
---------------------------------------------------------
350,192 95,9 360,982 98,9 10000 _do_pswd (pswd_x.obj)
5,700 1,6 5,700 1,6 10000 _CalculateCRC (pswd_x.obj)
5,090 1,4 10,790 3,0 10000 _CheckCRC (pswd_x.obj)
2,841 0,8 363,824 99,6 1 _gen_pswd (pswd_x.obj)
1,226 0,3 365,148 100,0 1 _main (pswd_x.obj)
0,098 0,0 0,098 0,0 1 _print_dot (pswd_x.obj)
В средней колонке (Func+Child Time) приводится полное время исполнения каждой функции, львиная доля которого принадлежит функции main (ну этого и следовало ожидать), за ней с минимальным отрывом следует gen_pswd со своими 99,6%, далее идет do_pswd - 98,9% и, сильно отставая от нее, где-то там на отшибе плетется CheckCRC, оттягивая на себя всего лишь 3,0%. А функцией CalculateCRC, с ее робким показателем 1,6%, на первый взгляд можно и вовсе пренебречь! Итак, судя по всему, мы имеем три "горячих" точки: main, gen_pswd и do_pswd (рис. 1.1).
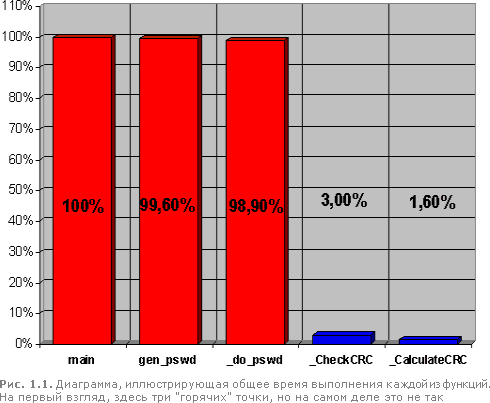
Впрочем, функцию main можно откинуть сразу. Она, понятное дело, ни в чем не "виновата". Остаются функции gen_pswd и do_pswd. Если бы это были абсолютно независимые функции, то "горячих" точек было бы и впрямь две, но в нашем случае это не так. И, если из полного времени выполнения функции gen_pswd, вычесть время выполнения ее дочерней функции do_pswd у "матери" останется всего лишь... 0,7%. Да! Меньше процента времени выполнения!
Обратимся к крайней левой колонке (листинг 1.1) таблицы профилировщика (Funct Time), чтобы подтвердить наши предположения. Действительно, в программе присутствует всего лишь одна "горячая" точка - do_pswd, и только ее оптимизация способна существенно увеличить быстродействие приложения (рис. 1.2).
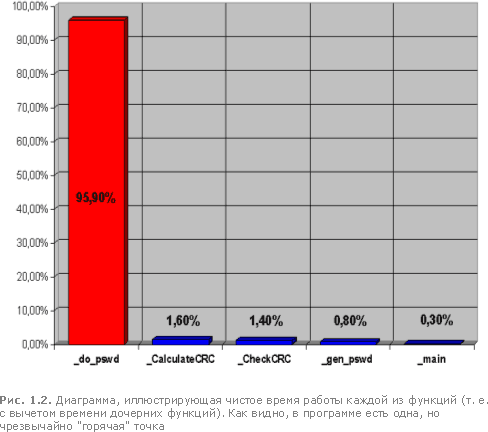
Хорошо, будем считать, что наиболее "горячая" функция определена и теперь мы горим желанием ее оптимизировать. А для этого недурно бы узнать картину распределения "температуры" внутри самой функции. К сожалению, профилировщик profile.exe (и другие подобные ему) не сможет ничем нам помочь, поскольку его разрешающая способность ограничивается именно функциями.
Но, на наше счастье существуют и более "продвинутые" профилировщики, уверенно различающие отдельные строки и даже машинные команды! К таким профилировщикам в частности относится VTune от Intel. Давайте запустим его и заглянем внутрь функции do_pswd (подробнее о технике работы с VTune см. "Практический сеанс профилировки с VTune").

Вот теперь совсем другое дело - сразу видно, что целесообразно оптимизировать, а что и без того уже "вылизано" по самые помидоры. "Горячие" точки главным образом сосредоточены вокруг конструкции pswd[p], - она очень медленно выполняется. Почему? Исходный текст не дает непосредственного ответа на поставленный вопрос и потому совсем не ясно: что конкретно следует сделать для понижения "температуры" "горячих" точек.
Приходится спускаться на уровень "голых" машинных команд (благо профилировщик VTune это позволяет). Вот, например, во что компилятор превратил безобидный на вид оператор присвоения pswd[p] = '!'
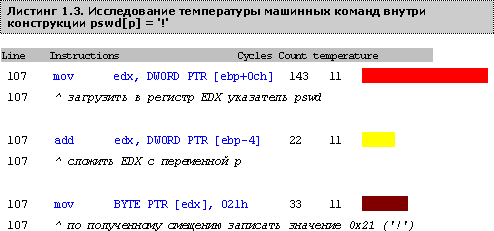
Смотрите! В одной строке исходного текста происходит целых три обращения к памяти! Сначала указатель pswd загружается в регистр EDX, затем он суммируется с переменной p, которая так же расположена в памяти, и лишь затем по рассчитанному смещению в память благополучно записывается константа '!' (021h).
Тем не менее, все равно остается не ясно, почему загрузка указателя pswd занимает столько времени? Может быть, кто-то постоянно вытесняет указатель pswd из кэша, заставляя процессор обращаться к медленной оперативной памяти? Так ведь нет! Программа работает с небольшим количеством переменных, заведомо умещающихся в кэше второго уровня.
Удельное время выполнения
Если время выполнения некоторой точки программы не постоянно, а варьируется в тех или иных пределах (например, в зависимости от рода обрабатываемых данных), то трактовка результатов профилировки становится неоднозначной, а сам результат - ненадежным. Для более достоверного анализа требуется: а) определить действительно ли в программе присутствуют подобные "плавающие" точки и, если да, то: б) определить время их исполнения в лучшем, худшем и среднем случаях.
Очень немногие профилировщики могут похвастаться способностью определять удельное время выполнения машинных команд (иначе называемое растактовкой). К счастью, профилировщик VTune это умеет! Обратимся к сгенерированному им протоколу динамического анализа. Быть может, он поможет нам разрешить загадку "неповоротливости" загрузки указателя pswd?

Ну, вот опять, - все команды, как команды, а загрузка указателя pswd "разлеглась" прямо как объевшаяся свинья, "сожравшая" целых тринадцать тактов, в то время как остальные свободно укладываются в один-два такта, а некоторые и вовсе занимают ноль, ухитряясь завершиться одновременно с предыдущей инструкций.
За исключением команды, загружающей содержимое переменной y в регистр ECX, время выполнения всех остальных команд строго постоянно и не меняется от случая к случаю. Наша же "подопечная" в зависимости от еще не выясненных обстоятельств, может "отъедать" даже восемьдесят тактов, что на время делает ее самой "горячей" точкой данного фрагмента программы. Восемьдесят тактов - это вообще полный беспредел! И пускай среднеарифметическое время ее выполнения составляет всего лишь семь тактов, а минимальное - и вовсе ноль, мы не успокоимся пока не выясним: на что и при каких именно обстоятельствах уходит такое количество тактов?
Информация о пенальти
Уже сам факт существования "горячей" точки говорит о том, что в программе что-то неправильно. Хорошо, если это чисто алгоритмическая ошибка, которую видно невооруженным глазом (например, наиболее узким местом приложения оказалась пузырьковая сортировка). Хуже, если процессорное время исчезает буквально на пустом месте без всяких видимых на то причин. Еще хуже, если "хищения" тактов происходят не систематически, а совершаются при строго определенном стечении каких-то неизвестных нам обстоятельств.
Возвратимся к предыдущему вопросу: почему указатель pswd загружается так долго? И при каких именно обстоятельствах загрузка переменной y "подскакивает" со своих обычных семи до восьмидесяти тактов? Судя по всему, процессору что-то не понравилось и он обложил эти две машинные команды "штрафом" (penalty), на время притормозив их исполнение. Можем ли мы узнать, когда и за какой "проступок" это произошло? Не прибегая к полной эмуляции процессора - вряд ли (хотя современные процессоры x86 с некоторыми ограничениями позволяют получить эту информацию и так).
Гранды компьютерной индустрии - Intel и AMD уже давно выпустили свои профилировщики, содержащие полноценные эмуляторы выпускаемых ими процессоров, позволяющие визуализировать нюансы выполнения каждой машинной инструкции.
Просто щелкните по строке mov ecx, DWORD PTR [ebp-28] и профилировщик VTune выдаст всю, имеющуюся у него информацию (листинг 1.5).
Листинг 1.5. Вывод профилировщиком VTune дополнительной информации о выполнении инструкции
Decoder Minimum Clocks = 1 ; Минимальное время декодирования - 1 такт
Decoder Average Clocks = 8.7 ; Эффективное время декодирования - 8,7 тактов
Decoder Maximum Clocks = 86 ; Максимальное время декодирования - 86 тактов
Retirement Minimum Clocks = 0, ; Минимальное время завершения - 0 тактов
Retirement Average Clocks = 7.3 ; Эффективное время завершения - 7,3 такта
Retirement Maximum Clocks = 80 ; Максимальное время завершения - 80 тактов
Total Cycles = 80 (00,65%) ; Всего времени исполнения - 80 тактов
Micro-Ops for this instruction = 1 ; Кол-во микроопераций в инструкции - 1
The instruction had to wait 0 cycles for it's sources to be ready
("Инструкция ждала 0 тактов пока подготавливались ее операнды, т.е.
попросту она их не ждала совсем")
Dynamic Penalty: IC_miss
The instruction was not in the instruction cache, so the processor
loads the instruction from the L2 cache or main memory.
("Инструкция отсутствовала в кодовом кэше, и процессор был вынужден
загружать ее из кэша второго уровня или основной оперативной памяти")
Occurances = 1 ; Такое случалось 1 раз
Dynamic Penalty: L2instr_miss
The instruction was not in the L2 cache, so the processor loads the
instruction from main memory.
("Инструкция отсутствовала в кэше второго уровня и процессор был вынужден
загружать ее из основной оперативной памяти")
Occurances = 1 ; Такое случалось 1 раз
Dynamic Penalty: Store_addr_unknown
The load instruction stalls due to the address calculation of the
previous store instruction.
("Загружающая инструкция простаивала по той причине, что адрес источника
рассчитывался предыдущей инструкцией записи")
Occurances = 10 ; Такое случалось 10 раз
Так, кажется, наше расследование превращается в самый настоящий детектив, еще более запутанный, чем у Агаты Кристи. Если приложить к полученному результату даже самый скромный арифметический аппарат, получится полная чепуха и полное расхождение "дебита с кредитом". Судите сами. Полное время выполнения инструкции - 80 тактов, причем, известно, что она выполнялась 11 раз (см. в листинге 1.3 колонку count отчета профилировщика). А наихудшее время выполнения инструкции составило... 80 тактов! А наихудшее время декодирования и вовсе - 86! То есть, худшее время декодирования инструкции превышает общее время ее исполнения и при этом в десяти итерациях она еще ухитряется простаивать как минимум один такт за каждую итерацию по причине занятости блока расчета адресов. Да... тут есть от чего "поехать крышей"!
Причина такого несоответствия заключается в относительности самого понятия времени. Вы думаете время относительно только у Эйнштейна? Отнюдь! В конвейерных процессорах (в частности процессорах Pentium и AMD K6/Athlon) понятие "времени выполнения инструкции" вообще не существует в принципе (см. подразд. " Конвейеризация или пропускная способность VS-латентность" гл. 1). В силу того, что несколько инструкций могут выполняться параллельно, простое алгебраическое суммирование времени их исполнения даст значительно больший результат, нежели исполнение занимает в действительности.
Ладно, оставим разборки с относительностью до более поздних времен, а пока обратим внимание на тот факт, что в силу отсутствия нашей инструкции в кэше (она как раз находится на границе двух кэш-линеек) и вытекающей отсюда необходимости загружать ее из основной памяти, в первой итерации цикла она выполняется значительно медленнее, чем во всех последующих. Отсюда, собственно, и берутся эти пресловутые восемьдесят тактов.
При большом количестве итераций (а при "живом" исполнении программы оно и впрямь велико) временем начальной загрузки можно и пренебречь, но... Стоп! Ведь профилировщик исполнил тело данного цикла всего 11 раз, в результате чего среднее время выполнения этой инструкции составило 7,3 тактов, что совершенно не соответствует реальной действительности!
Ой! Оказывается, это вовсе не "горячая" точка! И тут совершенного нечего оптимизировать. Если мы увеличим количество прогонов профилировщика хотя бы в четыре раза, среднее время выполнения нашей инструкции понизится до 1,8 тактов и она окажется одним из самых "холодных" мест программы! Точнее - это вообще абсолютный ноль, поскольку эффективное время исполнения данной инструкции - ноль тактов (т. е. она завершается одновременно с предыдущей машинной командой). Словом, мы "промахнулись" по полной программе.
Отсюда правило: прежде чем приступать к оптимизации, убедитесь, что количество прогонов программы достаточно велико для маскировки накладных расходов первоначальной загрузки.
Короткое лирическое отступление на тему: почему же все так произошло. По умолчанию VTune прогоняет профилируемый фрагмент 1.000 раз. Много? Не спешите с ответом. Наш хитрый цикл устроен так, что его тело получает управление лишь каждые 'z' '!' = 0x59 итераций (см. листинг 1.2). Таким образом, за все время анализа тело цикла будет исполнено всего лишь 1.000/89 = 11 раз! Причем, ни в коем случае нельзя сказать, что это надуманный пример. Напротив! В программном коде такое встречается сплошь и рядом.
Листинг 1.6. Демонстрация кода, некоторые участки которого прогоняются профилировщиком относительно небольшое количество раз, что искажает результат профилировки
while((++pswd[p])>'z') // _ данный цикл прогоняется профилировщиком 1.000 раз
{
pswd[p] = '!'; // _ данная инструкция прогоняется всего 11 раз
...
}
Поэтому, обнаружив "горячую" точку в первую очередь убедитесь, что количество ее прогонов достаточно велико. В противном случае полученный результат с большой степенью вероятности окажется недостоверным. И тут мы плавно переходим к обсуждению подсчета числа вызовов каждой точки программы.
Впрочем нет, постойте. Нам еще предстоит разобраться со второй "горячей" точкой и на удивление медленной скоростью загрузки указателя pswd. Опытные программисты, вероятно, уже догадались в чем тут дело.
Действительно, - строка pswd[p] = '!' - это первая строка тела цикла, получающая управление каждые 0x59 итераций, что намного превосходит "проницательность" динамического алгоритма предсказания ветвлений, используемого процессором для предотвращения остановки вычислительного конвейера.
Следовательно, данное ветвление всегда предсказывается ошибочно и выполнение этой инструкции процессору приходится начинать с нуля. А процессорный конвейер - длинный. Пока он заполниться... Собственно, тут виновата вовсе не команда mov edx, DWORD PTR [ebp+0ch] - любая другая команда на ее месте исполнялась бы столь же непроизводительно! "Паяльная грелка, до красна нагревающая" эту точку программы, находится совсем в другом месте!
Поднимем курсор чуть выше, на инструкцию условного перехода предшествующую этой команде, и дважды щелкнем мышкой. Профилировщик VTune выдаст следующую информацию:
Decoder Minimum Clocks = 0 ; Минимальное время декодирования - 0 тактов
Decoder Average Clocks = 0 ; Эффективное время декодирования - 0 тактов
Decoder Maximum Clocks = 4 ; Максимальное время декодирования - 4 такта
Retirement Average Clocks = 1 ; Эффективное время завершения - 1 такт
Total Cycles = 1011 (08,20%) ; Всего времени исполнения - 1010 тактов (8,2%)
Micro-Ops for this instruction = 1 ; Кол-во микроопераций в инструкции - 1
The instruction had to wait (8,11.1,113) cycles for it's sources to be ready
("Эта инструкция ждала минимально 8, максимально 113, а в
основном 11,1 тактов пока ее операнды не были готовы")
Dynamic Penalty: BTB_Miss_Penalty ; Штраф типа BTB_Miss_Penalty
This instruction stalls because the branch was mispredicted.
("Эта инструкция простаивала потому что ветвление не было предсказано")
Occurances = 13 ; Такое случалось 13 раз
Наша гипотеза полностью подтверждается. Это ветвление тринадцать раз предсказывалось неправильно, о чем VTune и свидетельствует! Постой, как тринадцать?! Ведь тело цикла исполняется только одиннадцать! Да, правильно, одиннадцать. Но ведь процессор наперед этого не знал, и дважды пытался передать на него управление, и лишь затем, "увидев", что ни одно из двух предсказаний не сбылось, "плюнул и поклялся", что никогда-никогда не поставит свои фишки на эту ветку.
ОК. Когда загадки разрешаются - это приятно. Но главный вопрос несколько в другом: как именно их разрешать? Хорошо, что в нашем случае непредсказуемый условный переход находился так близко к "горячей" точке, но ведь в некоторых (и не таких уж редких) случаях "виновник" бывает расположен даже в других модулях программы! Ну что на это сказать... Подходите к профилировке комплексно и всегда думайте головой. Пожалуй, ничего более действенного я не смогу посоветовать...
Определение количества вызовов
Как мы только что показали, определение количества вызовов профилируемой точки необходимо уже хотя бы для того, чтобы мы могли убедиться в достоверности изменений. К тому же, оценивать температуру точки можно не только по времени ее выполнения, но и частоте вызова.
Например, пусть у нас есть две "горячие" точки, в которых процессор проводит одинаковое время, но первая из них вызывается сто раз, а вторая - сто тысяч раз. Нетрудно догадаться, что, оптимизировав последнюю хотя бы на 1%, мы получим колоссальный выигрыш в производительности, в то время как, сократив время выполнения первой из них вдвое, мы ускорим нашу программу всего лишь на четверть.
Таким образом, часто вызываемые функции в большинстве случаев имеет смысл "инлайнить" (от английского in-line), т. е. непосредственно вставить их код в тело вызываемых функций, что сэкономит какое-то количество времени.
Определять количество вызовов умеют практически все профилировщики, и тут нет никаких проблем, заслуживающих нашего внимания.
Определение степени покрытия
Вообще-то говоря, определение степени покрытия не имеет никакого отношения к оптимизации приложений и это побочная функция профилировщиков. Но, поскольку она все-таки есть, мораль обязывает автора рассмотреть ее, хоть и кратко.
Итак, покрытие - это процент реально выполненного кода программы в процессе его профилировки. Кому нужна такая информация? Ну, в первую очередь, тестерам - должны же они убедиться, что весь код приложения протестирован целиком и в нем не осталось никаких "темных" мест.
С другой стороны, оптимизируя программу, очень важно знать, какие именно ее части были профилированы, а какие нет. В противном случае многих "горячих" точек можно просто не заметить только потому, что соответствующие им ветки программы вообще ни разу не получили управления!
Рассмотрим, например, как может выглядеть протокол покрытия функций, сгенерированный профилировщиком profile.exe для нашего тестового примера pswd.exe (о самом тестовом примере см. разд. "Практический сеанс профилировки с VTune в десяти шагах" гл. 2)
Листинг 1.7. Пример протокола покрытия функций, сгенерированный профилировщиком profile
Program Statistics ; Статистика по программе
------------------
Command line at 2002 Aug 20 03:36: pswd ; командная строка
Call depth: 2 ; глубина вызовов: 2
Total functions: 5 ; всего функций: 5
Function coverage: 60,0% ; покрыто функций: 60%
Module Statistics for pswd.exe ; статистика по модулю pswd
------------------------------
Functions in module: 5 ; функций в модуле: 5
Module function coverage: 60,0% ; функций прокрыто: 60%
Covered Function ; порытые функции
----------------
. _DeCrypt (pswd.obj)
. __real@4@4008fa00000000000000 (pswd.obj)
* _gen_pswd (pswd.obj)
* _main (pswd.obj)
* _print_dot (pswd.obj)
Из листинга 1.7 следует, что лишь 60% функций получили управление, а остальные 40% не были вызваны ни разу! Разумно убедиться: а вызываются ли эти функции когда ни будь вообще или представляют собой "мертвый" код, который можно безболезненно удалить из программы, практически на половину уменьшив ее в размерах?
Если же эти функции при каких-то определенных обстоятельствах все же получают управление, нам необходимо проанализировать исходный код, чтобы разобраться: что же это за обстоятельства и воссоздать их, чтобы профилировщик смог пройти и остальные участки программы. Имена покрытых и непокрытых функций перечислены в секции Covered Function. Покрытые отмечаются знаком "*", а непокрытые - "."
Вообще же, для определения степени покрытия существует множество узкоспециализированных приложений (например, NuMega Code Coverage), изначально направленных на решение именно этой задачи и со своей работой они справляются намного лучше любого профилировщика.
Фундаментальные проблемы профилировки "в малом"
Профилировкой "в малом" мы будем называть измерение времени выполнения небольших фрагментов программы, а то и отдельных машинных команд.
Профилировке в малом присущ ряд серьезных и практически неустранимых проблем, незнание которых зачастую приводит к грубым ошибкам интерпретации результата профилировки и как следствие - впустую потраченному времени и гораздо худшему качеству оптимизации.
Конвейеризация или пропускная способность VS-латентность
Начнем с того, что в конвейерных системах такого понятия как "время выполнения одной команды" просто нет. Уместно провести такую аналогию. Допустим, некоторый приборостроительный завод выпускает шестьсот микросхем памяти в час. Ответьте: сколько времени занимает производство одной микросхемы? Шесть секунд? Ну конечно же нет! Полный технологический цикл составляет не секунды, и даже не дни, а месяцы! Мы не замечаем этого лишь благодаря конвейеризации производства, т. е. разбиении его на отдельные стадии, через которые в каждый момент времени проходит, по крайней мере, одна микросхема.
Количество продукции, сходящей с конвейера в единицу времени, называют его пропускной способностью. Легко показать, что пропускная способность в общем случае обратно пропорциональна длительности одной стадии, - действительно, чем короче каждая стадия, тем чаще продукция сходит с конвейера. При этом количество самих стадий (попросту говоря, длина конвейера) не играет абсолютно никакой роли. Кстати, обратите внимание, что практически на всех заводах каждая стадия представляет собой элементарную операцию, - вроде "накинуть ключ на гайку" или "стукнуть молотком". И не только потому, что человек лучше приспосабливается к однообразной монотонной работе (наоборот, он, в отличии от автоматов, ее терпеть не может!). Элементарные операции, занимая чрезвычайно короткое время, обеспечивают конвейеру максимальную пропускную способность.
Той же самой тактики придерживаются и производители процессоров, причем заметна ярко выраженная тенденция увеличения длины конвейера в каждой новой модели. Так, если в первых Pentium длина конвейера составляла всего пять стадий, то уже в Pentium-II она была увеличена до четырнадцати стадий, а в Pentium-4 - и вовсе до двадцати. Такая мера была вызвана чрезмерным наращиванием тактовой частоты ядра процессора и вытекающей отсюда необходимостью как-то заставить конвейер работать на этой частоте.
С одной стороны и хорошо, - конвейер крутится как угорелый, выполняя до 6 микроинструкций за такт и какое нам собственно дело до его длины? А вот какое! Вернемся к нашей аналоги с приборостроительным заводом. Допустим, захотелось нам запустить в производство новую модель. Вопрос: через какое время она сойдет с конвейера? (Бюрократическими проволочками можно пренебречь). Ни через шесть секунд, ни через час новая модель готова не будет и придется ждать пока весь технологический цикл не завершится целиком.
Латентность - т. е. полное время прохождения продукции по конвейеру, может быть и не критична для неповоротливого технологического процесса производства (действительно, новые модели микросхем не возникают каждый день), но весьма ощутимо влияет на быстродействие динамичного процессора, обрабатывающего неоднородный по своей природе код. Продвижение машинных инструкций по конвейеру сопряжено с рядом принципиальных трудностей, - то не готовы операнды, то занято исполнительное устройство, то встретился условный переход (что равносильно переориентации нашего приборостроительного завода на производство новой модели) и... вместо безостановочного вращения конвейера мы наблюдаем его длительные простои, лишь изредка прерываемые короткими рывками, а затем вновь покой и тишина.
В лучшем случае время выполнения одной инструкции определяется пропускной способностью конвейера, а в худшем - его латентностью. Поскольку пропускная способность и латентность различаются где-то на порядок или около того, бессмысленно говорить о среднем времени выполнения инструкции. Оно не будет соответствовать никакой физической действительности.
Малоприятным следствием становится невозможность определения реального времени исполнения компактного участка кода (если, конечно, не прибегать к эмуляции процессора). До тех пор, пока время выполнения участка кода не превысит латентность конвейера (30 тактов для P6), мы вообще ничего не сможем сказать ни о коде, ни о времени, ни о конвейере!
Неточность измерений
Одно из фундаментальных отличий цифровой от аналоговой техники заключается в том, что верхняя граница точности цифровых измерений определяется точностью измерительного инструмента (точность аналоговых измерительных инструментов, напротив, растет с увеличением количества замеров).
А чем можно измерять время работы отдельных участков программы? В персональных компьютерах семейства IBM PC AT имеются как минимум два таких механизма: системный таймер (штатная скорость: 18,2 тика в секунду, т. е. 55 мс, максимальная скорость - 1 193 180 тиков в секунду или 0,84 мкс), часы реального времени (скорость 1024 тика в секунду т. е. 0,98 мс). В дополнении к этому в процессорах семейства Pentium появился так называемый регистр счетчик - времени (Time Stamp Counter), увеличивающийся на единицу при каждом такте процессорного ядра.
Теперь разберемся со всем этим хозяйством подробнее. Системный таймер (с учетом времени, расходующегося на считывание показаний) обеспечивает точность порядка 5 мс, что составляет более двух десятков тысяч тактов даже в системе с частотой 500 МГц! Это - целая вечность для процессора. За это время он успевает перемолотить море данных, скажем, отсортировать сотни полторы чисел. Поэтому, системный таймер для профилирования отдельных функций непригоден. В частности, нечего и надеяться с его помощью найти узкие места функции quick sort! Да что там узкие места - при небольшом количестве обрабатываемых чисел он и общее время сортировки определяет весьма неуверенно.
Причем, прямого доступа к системному таймеру под нормальной операционной системой никто не даст, а минимальный временной интервал, еще засекаемый штатной Си-функций clock(), составляет всего лишь 1/100 сек, а это годиться разве что для измерения времени выполнения всей программы целиком.
Точность часов реального времени так же вообще не идет ни в какое сравнение с точность системного таймера (перепрограммированного, разумеется).
Остается надеяться лишь на Time Stamp Counter. Первое знакомство с ним вызывает просто бурю восторга и восхищения "ну наконец-то Intel подарила нам то, о чем мы так долго мечтали!". Судите сами: во-первых, операционные системы семейства Windows (в том числе и "драконическая" в этом плане NT) предоставляют беспрепятственный доступ к машинной команде RDTSC, читающий содержимое данного регистра. Во-вторых, поскольку он инкрементируется каждый такт, создается обманчивое впечатление, что с его помощью возможно точно определять время выполнения каждой команды процессора. Увы! На самом же деле это далеко не так!
Начнем с того, что в конвейерных системах, как мы уже помним, вообще нет такого понятия как время выполнения команды, и следует говорить либо о пропускной способности, либо латентности. Сразу же возникает вопрос: а что же все-таки команда RDTSC меряет? Документация Intel не дает прямого ответа, но судя по всему, RDTSC считывает содержимое регистра счетчика-времени в момент прохождения данной инструкции через соответствующее исполнительное устройство. Причем, RDTSC - это неупорядоченная команда, т. е. она может завешаться даже раньше предшествующих ей команд. Именно так и произойдет, если предшествующая ей команда простаивает в ожидании операндов.
Рассмотрим крайний случай, когда измеряется время выполнения минимальной порции кода (одна машинная команда уходит на то, чтобы сохранить считанное значение в первой итерации):
Листинг 1.8. Попытка замера времени выполнения одной машинной команды
RDTSC ; читаем значение регистра времени
; и помещаем его в регистры EDX и EAX
MOV [clock], EAX ; сохраняем младшее двойное слово
; регистра времени в переменную clock
RDTSC ; читаем регистр времени еще раз
SUB EAX, [clock] ; вычисляем разницу замеров между
; первым и вторым замером
При прогоне этого примера на P-III он выдаст 32 такта, вызывая тем самым риторический вопрос: "а почему, собственно, так много?" Хорошо, оставим выяснение обстоятельств "похищения процессорных тактов" до лучших времен, а сейчас попробуем измерять время выполнения какой-нибудь машинной команды, ну скажем, INC EAX, увеличивающей значение регистра EAX на единицу. Поместим ее между инструкциями RDTSC и перекомпилируем программу.
Вот это да! Прогон показывает все те же 32 такта. Странно! Добавим-ка мы еще одну INC EAX. Как это так - снова 32 такта?! Зато при добавлении сразу трех инструкций INC EAX контрольное время исполнения скачкообразно увеличивается на единицу, что составляет 33 такта. Четыре и пять инструкций INC EAX дадут аналогичный результат, а вот при добавлении шестой, результат изменений вновь возрастает на один такт.
Но ведь процессор Pentium, имея в наличии всего лишь одно арифметическое устройство, никак не может выполнять более одного сложения за такт одновременно! Полученное нами значение в три команды за такт - это скорость их декодирования, но отнюдь не исполнения! Чтобы убедиться в этом запустим на выполнение следующий цикл (листинг 1.9).
Листинг 1.9. Измерение времени выполнения 6х1000 машинных команд INC
MOV ECX,1000 ; поместить в регистр ECX значение 1000 @for: ; метка начала цикла INC EAX ;\ INC EAX ; +- одна группа профилируемых инструкций INC EAX ;/ INC EAX ;\ INC EAX ; +- вторая группа профилируемых инструкций INC EAX ;/ DEC ECX ; уменьшить значение регистра ECX на 1 ; (здесь он используется в качестве ; счетчика цикла) JNZ @xxx ; до тех пор, пока ECX не обратится в ноль ; перепрыгивать на метку @for
На P-III выполнение данного цикла займет отнюдь не ~2 000, а целых 6 781 тактов, что соответствует, по меньшей мере, одному такту, приходящемуся на каждую математическую инструкцию! Следовательно, в предыдущем случае, при измерении времени выполнения нескольких машинных команд, инструкция RDTSC "вперед батьки пролезла в пекло", сообщив нам совсем не тот результат, которого мы от нее ожидали!
Вот если бы существовал способ "притормозить" выполнение инструкции RDTSC до тех пор, пока полностью не будут завершены все предшествующие ей машинные инструкции... И такой способ есть! Достаточно поместить перед RDTSC одну из команд упорядоченного выполнения. Команды упорядоченного выполнения начинают обрабатываться только после схода с конвейера последней предшествующей ей неупорядоченной команды и, до тех пор пока команда упорядоченного выполнения не завершится, следующие за ней команды мирно дожидаются своей очереди, а не "лезут как толпа дикарей" вперед на конвейер.
Подавляющее большинство команд упорядоченного выполнения - это привилегированные команды (например, инструкции чтения/записи портов ввода-вывода) и лишь очень немногие из них доступны с прикладного уровня. В частности, к таковым принадлежит инструкция идентификации процессора CPUID.
Многие руководства (в частности и Ангер Фог в своем руководстве "How to optimize for the Pentium family of microprocessors" и технический документ "Using the RDTSC Instruction for Performance Monitoring" от корпорации Intel) предлагают использовать приблизительно такой код (листинг 1.10).
Листинг 1.10. Официально рекомендованный способ вызова инструкции RDTSC для измерения времени выполнения
XOR EAX,EAX ; вызываем машинную команду CPUID, CPUID ; после выполнения которой все ; предыдущие машинные инструкции ; гарантированно сошли к конвейера ; и потому никак не могут повлиять ; на результаты наших замеров RDTSC ; вызываем инструкцию RDTSC, которая ; возвращает в регистре EAX младшее ; двойное слово текущего значения ; Time Stamp Counter 'a MOV [clock],EAX ; сохраняем полученное только что ; значение в переменной clock // ... ;\ // профилируемый код ; +-здесь исполняется профилируемый код // ... ;/ XOR EAX,EAX ; еще раз выполняем команду CPUID, CPUID ; чтобы все предыдущие инструкции ; гарантированно успели покинуть ; конвейер RDTSC ; вызываем инструкцию RDTSC для чтения ; нового значение Time Stamp Count SUB EAX,[clock] ; вычисляем разность второго и первого ; замеров, тем самым определяя реальное ; время выполнения профилируемого ; фрагмента кода
К сожалению, даже этот, официально рекомендованный, код все равно не годится для измерения времени выполнения отдельных инструкций, поскольку полученный с его помощью результат представляет собой полное время выполнения инструкции, т. е. ее латентность, а отнюдь не пропускную способность, которая нас интересует больше всего.
(Кстати, и у Intel, и Ангера Фога есть одна грубая ошибка - в их варианте программы перед инструкцией CPUID отсутствует явное задание аргумента, который эта инструкция ожидает "увидеть" в регистре EAX. А, поскольку, время ее выполнения зависит от аргумента, то и время выполнения профилируемого фрагмента не постоянно, а зависит от состояния регистров на входе и выходе. В предлагаемом мною варианте инициализация EAX осуществляется явно, что страхует профилировщик от всяких там наведенных эффектов).
Имеется и другая проблема, еще более серьезная, чем первая. Вы помните постулат квантовой физики, сводящийся к тому, что всякое измерение свойств объекта неизбежно вносит в этот объект изменения, искажающие результат измерений? Причем, эти искажения невозможно устранить простой калибровкой, поскольку изменения могут носить не только количественный, но и качественный характер.
Если профилируемый код задействует те же самые узлы процессора, что и команды RDTSC/CPUID, время его выполнения окажется совсем иным нежели в действительности! Никаким ухищрениями нам не удастся достигнуть точности измерений до одного-двух тактов!
Поэтому, минимальный промежуток времени, которому еще можно верить, составляет, как показывает практика и личный опыт автора, по меньше мере пятьдесят-сто тактов.
Отсюда следствие: штатными средствами процессора измерять время выполнения отдельных команд невозможно.
Аппаратная оптимизация
На мгновение отвлечемся от компьютеров и зададимся вопросом: можно ли с помощью обычной ученической линейки измерить толщину листа принтерной бумаги? На первый взгляд, тут без штангенциркуля ну никак не обойтись... Но, если взять с полсотни листов бумаги и плотно сложить их друг с другом... вы уже поняли куда я клоню? Пусть погрешность измерения толщины образовавшегося "кирпича" бумаги составит 1 мм, тогда - точность определения толщины каждого отдельно взятого листа будет не хуже чем 0,02 мм, что вполне достаточно для большинства повседневных целей!
Почему бы ни применить эту технику для измерения времени выполнения машинных команд? В самом деле, время выполнения одной команды так мало, что просто ничем его не измерить (см. подразд. "Неточность измерений"), но если мы возьмем сто или даже сто тысяч таких команд, то... Но, увы! Машинные команды ведут себя совсем не так, как листы бумаги. Неоднородность конвейера приводит к тому, что зависимость между количеством и временем выполнения команд носит ярко выраженный нелинейный характер.
К тому же, современные процессоры слишком умны, чтобы воспринимать переданный им на выполнение код буквально. Нет! Они подходят к этому делу весьма творчески. Вот, допустим, встретится им последовательность команд MOV EAX, 1; MOV EAX, 1; MOV EAX, 1, каждая из которых помещает в регистр EAX значение "1". Думаете, процессор как полный недоумок, исполнит все три команды? Да как бы не так! Поскольку, результат двух первых присвоений никак не используется, процессор отбросит эти команды как ненужные, затратив время лишь на их декодирование, и ощутимо сэкономит на их выполнении!
Оптимизация программного кода, выполняемая процессором на аппаратном уровне, значительно увеличивает производительность системы, занижая тем самым фактическое время выполнения машинных команд. Да, мы можем точно измерять сколько тактов выполнялся блок из тысячи таких-то команд, но следует с большой осторожностью подходить к оценке времени выполнения одной такой команды.
Низкая "разрешающая способность"
Учитывая, что пропускная способность большинства инструкций составляет всего один такт, а минимальный промежуток времени, который еще можно измерять, находится в районе пятидесяти - ста тактов, предельная разрешающая способность не эмулирующих профилировщиков не превышает полста команд.
Под "разрешающей способностью" здесь и далее понимается протяженность "горячей" точки более или менее уверенно распознаваемой профилировщиком.
Строго говоря, не эмулирующие профилировщики показывают не саму "горячую" точку, а некоторую протяжную область, к которой эта "горячая" точка принадлежит.
Фундаментальные проблемы профилировки "в большом"
Профилировкой "в большом" мы будем называть измерение времени выполнения структурных единиц программы (функций, многократно выполняемых циклов и т.д.), а то и всей программы целиком.
Профилировке "в большом" присущи свои проблемы. Это и непостоянство времени выполнения, и проблема "второго прохода", и необходимость учета наведенных эффектов... Словом, здесь есть над чем поработать!
Непостоянства времени выполнения
Если вы профилировали приложения и раньше, то наверняка сталкивались с тем, что результаты измерений времени выполнения варьируются от прогона к прогону, порой отличаясь один от другого более чем значительно.
Причин такого непостоянства существует, по меньшей мере, две:
- программное непостоянство, связанное с тем, что в многозадачных операционных системах (в частности в Windows) профилируемая программа попадает под влияние чрезвычайно изменчивой окружающей среды;
- аппаратное непостоянство, вызванное внутренней "многозадачностью" самого железа.
В силу огромной их значимости для результатов профилировки, обе этих причины далее будут рассмотрены во всех подробностях.